Merge branch 'main' of github.com:infiniflow/ragflow into feature/1111
# Conflicts: # web/public/iconfont.js # web/src/components/svg-icon.tsx # web/src/locales/en.ts # web/src/locales/zh.ts # web/src/pages/login-next/index.tsx # web/src/pages/user-setting/data-source/contant.tsx
This commit is contained in:
commit
a5a82f0f4e
38 changed files with 60 additions and 60 deletions
|
|
@ -48,7 +48,7 @@ It consists of a server-side Service and a command-line client (CLI), both imple
|
||||||
1. Ensure the Admin Service is running.
|
1. Ensure the Admin Service is running.
|
||||||
2. Install ragflow-cli.
|
2. Install ragflow-cli.
|
||||||
```bash
|
```bash
|
||||||
pip install ragflow-cli==0.21.1
|
pip install ragflow-cli==0.22.0
|
||||||
```
|
```
|
||||||
3. Launch the CLI client:
|
3. Launch the CLI client:
|
||||||
```bash
|
```bash
|
||||||
|
|
|
||||||
|
|
@ -378,7 +378,7 @@ class AdminCLI(Cmd):
|
||||||
self.session.headers.update({
|
self.session.headers.update({
|
||||||
'Content-Type': 'application/json',
|
'Content-Type': 'application/json',
|
||||||
'Authorization': response.headers['Authorization'],
|
'Authorization': response.headers['Authorization'],
|
||||||
'User-Agent': 'RAGFlow-CLI/0.21.1'
|
'User-Agent': 'RAGFlow-CLI/0.22.0'
|
||||||
})
|
})
|
||||||
print("Authentication successful.")
|
print("Authentication successful.")
|
||||||
return True
|
return True
|
||||||
|
|
|
||||||
|
|
@ -109,8 +109,8 @@ SVR_MCP_PORT=9382
|
||||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.0
|
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.0
|
||||||
|
|
||||||
# If you cannot download the RAGFlow Docker image:
|
# If you cannot download the RAGFlow Docker image:
|
||||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.21.1
|
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.22.0
|
||||||
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.21.1
|
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.22.0
|
||||||
#
|
#
|
||||||
# - For the `nightly` edition, uncomment either of the following:
|
# - For the `nightly` edition, uncomment either of the following:
|
||||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly
|
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly
|
||||||
|
|
|
||||||
|
|
@ -97,7 +97,7 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
||||||
- `SVR_HTTP_PORT`
|
- `SVR_HTTP_PORT`
|
||||||
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
||||||
- `RAGFLOW-IMAGE`
|
- `RAGFLOW-IMAGE`
|
||||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.21.1` (the RAGFlow Docker image without embedding models).
|
The Docker image edition. Defaults to `infiniflow/ragflow:v0.22.0` (the RAGFlow Docker image without embedding models).
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
If you cannot download the RAGFlow Docker image, try the following mirrors.
|
If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||||
|
|
|
||||||
|
|
@ -47,7 +47,7 @@ After building the infiniflow/ragflow:nightly image, you are ready to launch a f
|
||||||
|
|
||||||
1. Edit Docker Compose Configuration
|
1. Edit Docker Compose Configuration
|
||||||
|
|
||||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.21.1` to `infiniflow/ragflow:nightly` to use the pre-built image.
|
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.22.0` to `infiniflow/ragflow:nightly` to use the pre-built image.
|
||||||
|
|
||||||
|
|
||||||
2. Launch the Service
|
2. Launch the Service
|
||||||
|
|
|
||||||
|
|
@ -60,7 +60,7 @@ Where:
|
||||||
|
|
||||||
### Transports
|
### Transports
|
||||||
|
|
||||||
The RAGFlow MCP server supports two transports: the legacy SSE transport (served at `/sse`), introduced on November 5, 2024 and deprecated on March 26, 2025, and the streamable-HTTP transport (served at `/mcp`). The legacy SSE transport and the streamable HTTP transport with JSON responses are enabled by default. To disable either transport, use the flags `--no-transport-sse-enabled` or `--no-transport-streamable-http-enabled`. To disable JSON responses for the streamable HTTP transport, use the `--no-json-response` flag.
|
The RAGFlow MCP server supports two transports: the legacy SSE transport (served at `/sse`), introduced on November 5, 2024, and deprecated on March 26, 2025, and the streamable-HTTP transport (served at `/mcp`). The legacy SSE transport and the streamable HTTP transport with JSON responses are enabled by default. To disable either transport, use the flags `--no-transport-sse-enabled` or `--no-transport-streamable-http-enabled`. To disable JSON responses for the streamable HTTP transport, use the `--no-json-response` flag.
|
||||||
|
|
||||||
### Launch from Docker
|
### Launch from Docker
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -193,7 +193,7 @@ This error suggests that you do not have Internet access or are unable to connec
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
### `WARNING: can't find /raglof/rag/res/borker.tm`
|
### `WARNING: can't find /ragflow/rag/res/borker.tm`
|
||||||
|
|
||||||
Ignore this warning and continue. All system warnings can be ignored.
|
Ignore this warning and continue. All system warnings can be ignored.
|
||||||
|
|
||||||
|
|
@ -413,7 +413,7 @@ See [here](./guides/models/deploy_local_llm.mdx) for more information.
|
||||||
|
|
||||||
For a locally deployed RAGFlow: the total file size limit per upload is 1GB, with a batch upload limit of 32 files. There is no cap on the total number of files per account. To update this 1GB file size limit:
|
For a locally deployed RAGFlow: the total file size limit per upload is 1GB, with a batch upload limit of 32 files. There is no cap on the total number of files per account. To update this 1GB file size limit:
|
||||||
|
|
||||||
- In **docker/.env**, upcomment `# MAX_CONTENT_LENGTH=1073741824`, adjust the value as needed, and note that `1073741824` represents 1GB in bytes.
|
- In **docker/.env**, uncomment `# MAX_CONTENT_LENGTH=1073741824`, adjust the value as needed, and note that `1073741824` represents 1GB in bytes.
|
||||||
- If you update the value of `MAX_CONTENT_LENGTH` in **docker/.env**, ensure that you update `client_max_body_size` in **nginx/nginx.conf** accordingly.
|
- If you update the value of `MAX_CONTENT_LENGTH` in **docker/.env**, ensure that you update `client_max_body_size` in **nginx/nginx.conf** accordingly.
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
|
|
|
||||||
|
|
@ -24,7 +24,7 @@ The service status page displays of all services within the RAGFlow system.
|
||||||
- **Search**: Use the search bar to quickly find services by **Name** or **Service Type**.
|
- **Search**: Use the search bar to quickly find services by **Name** or **Service Type**.
|
||||||
- **Actions** (hover over a row to see action buttons):
|
- **Actions** (hover over a row to see action buttons):
|
||||||
- **Extra Info**: Display additional configuration information of a service in a dialog.
|
- **Extra Info**: Display additional configuration information of a service in a dialog.
|
||||||
- **Service Details**: Display detailed status information of a service in a dialog. According to services's type, a service's status information could be displayed as a plain text, a key-value data list, a data table or a bar chart.
|
- **Service Details**: Display detailed status information of a service in a dialog. According to service's type, a service's status information could be displayed as a plain text, a key-value data list, a data table or a bar chart.
|
||||||
|
|
||||||
|
|
||||||
### User management
|
### User management
|
||||||
|
|
|
||||||
|
|
@ -59,7 +59,7 @@ The **+ Add tools** and **+ Add agent** sections are used *only* when you need t
|
||||||
|
|
||||||
### 6. Choose the next component
|
### 6. Choose the next component
|
||||||
|
|
||||||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
When necessary, click the **+** button on the **Agent** component to choose the next component in the workflow from the dropdown list.
|
||||||
|
|
||||||
## Connect to an MCP server as a client
|
## Connect to an MCP server as a client
|
||||||
|
|
||||||
|
|
@ -97,7 +97,7 @@ Update your MCP server's name, URL (including the API key), server type, and oth
|
||||||
|
|
||||||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||||
|
|
||||||
### 6. View the availabe tools of your MCP server
|
### 6. View the available tools of your MCP server
|
||||||
|
|
||||||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||||
|
|
||||||
|
|
@ -113,7 +113,7 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
- **Model**: The chat model to use.
|
- **Model**: The chat model to use.
|
||||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
This parameter has three options:
|
This parameter has three options:
|
||||||
- **Improvise**: Produces more creative responses.
|
- **Improvise**: Produces more creative responses.
|
||||||
- **Precise**: (Default) Produces more conservative responses.
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
|
@ -137,7 +137,7 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creativity**.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
### System prompt
|
### System prompt
|
||||||
|
|
|
||||||
|
|
@ -42,7 +42,7 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
- **Model**: The chat model to use.
|
- **Model**: The chat model to use.
|
||||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
This parameter has three options:
|
This parameter has three options:
|
||||||
- **Improvise**: Produces more creative responses.
|
- **Improvise**: Produces more creative responses.
|
||||||
- **Precise**: (Default) Produces more conservative responses.
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
|
@ -66,7 +66,7 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creativity**.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
### Message window size
|
### Message window size
|
||||||
|
|
|
||||||
|
|
@ -163,7 +163,7 @@ pandas
|
||||||
requests
|
requests
|
||||||
openpyxl # here it is
|
openpyxl # here it is
|
||||||
|
|
||||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the image and start the service immediately. To build image only, using `make build` instead.
|
||||||
|
|
||||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_python_0 /bin/bash # entering container to check if the package is installed
|
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_python_0 /bin/bash # entering container to check if the package is installed
|
||||||
|
|
||||||
|
|
@ -189,7 +189,7 @@ To import your JavaScript packages, navigate to `sandbox_base_image/nodejs` and
|
||||||
|
|
||||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
||||||
|
|
||||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the image and start the service immediately. To build image only, using `make build` instead.
|
||||||
|
|
||||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_nodejs_0 /bin/bash # entering container to check if the package is installed
|
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_nodejs_0 /bin/bash # entering container to check if the package is installed
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -40,12 +40,12 @@ For dynamic SQL queries, you can include variables in your SQL queries, such as
|
||||||
|
|
||||||
### Database type
|
### Database type
|
||||||
|
|
||||||
The supported database type. Currently the following database types are available:
|
The supported database type. Currently, the following database types are available:
|
||||||
|
|
||||||
- MySQL
|
- MySQL
|
||||||
- PostreSQL
|
- PostgreSQL
|
||||||
- MariaDB
|
- MariaDB
|
||||||
- Microsoft SQL Server (Myssql)
|
- Microsoft SQL Server (Mssql)
|
||||||
|
|
||||||
### Database
|
### Database
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -9,7 +9,7 @@ A component that sets the parsing rules for your dataset.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
A **Parser** component is auto-populated on the ingestion pipeline canvas and required in all ingestion pipeline workflows. Just like the **Extract** stage in the traditional ETL process, a **Parser** component in an ingestion pipeline defines how various file types are parsed into structured data. Click the component to display its configuration panel. In this configuration panel, you set the parsing rules for various file types.
|
A **Parser** component is autopopulated on the ingestion pipeline canvas and required in all ingestion pipeline workflows. Just like the **Extract** stage in the traditional ETL process, a **Parser** component in an ingestion pipeline defines how various file types are parsed into structured data. Click the component to display its configuration panel. In this configuration panel, you set the parsing rules for various file types.
|
||||||
|
|
||||||
## Configurations
|
## Configurations
|
||||||
|
|
||||||
|
|
@ -39,7 +39,7 @@ The output of a PDF parser is `json`. In the PDF parser, you select the parsing
|
||||||
- [Docling](https://github.com/docling-project/docling): (Experimental) An open-source document processing tool for gen AI.
|
- [Docling](https://github.com/docling-project/docling): (Experimental) An open-source document processing tool for gen AI.
|
||||||
- A third-party visual model from a specific model provider.
|
- A third-party visual model from a specific model provider.
|
||||||
|
|
||||||
:::danger IMPORTANG
|
:::danger IMPORTANT
|
||||||
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a client for MinerU, calling it to parse documents, reading the output files, and ingesting the parsed content. To use this feature, follow these steps:
|
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a client for MinerU, calling it to parse documents, reading the output files, and ingesting the parsed content. To use this feature, follow these steps:
|
||||||
|
|
||||||
1. Prepare MinerU:
|
1. Prepare MinerU:
|
||||||
|
|
|
||||||
|
|
@ -61,7 +61,7 @@ Click the **Run** button on the top of canvas to test the retrieval results.
|
||||||
|
|
||||||
### 7. Choose the next component
|
### 7. Choose the next component
|
||||||
|
|
||||||
When necessary, click the **+** button on the **Retrieval** component to choose the next component in the worflow from the dropdown list.
|
When necessary, click the **+** button on the **Retrieval** component to choose the next component in the workflow from the dropdown list.
|
||||||
|
|
||||||
|
|
||||||
## Configurations
|
## Configurations
|
||||||
|
|
|
||||||
|
|
@ -24,7 +24,7 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
- **Model**: The chat model to use.
|
- **Model**: The chat model to use.
|
||||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
This parameter has three options:
|
This parameter has three options:
|
||||||
- **Improvise**: Produces more creative responses.
|
- **Improvise**: Produces more creative responses.
|
||||||
- **Precise**: (Default) Produces more conservative responses.
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
|
|
||||||
|
|
@ -17,7 +17,7 @@ An Agent’s response time generally depends on many factors, e.g., the LLM’s
|
||||||
|
|
||||||
- For simple tasks, such as retrieval, rewriting, formatting, or structured data extraction, use concise prompts, remove planning or reasoning instructions, enforce output length limits, and select smaller or Turbo-class models. This significantly reduces latency and cost with minimal impact on quality.
|
- For simple tasks, such as retrieval, rewriting, formatting, or structured data extraction, use concise prompts, remove planning or reasoning instructions, enforce output length limits, and select smaller or Turbo-class models. This significantly reduces latency and cost with minimal impact on quality.
|
||||||
|
|
||||||
- For complex tasks, like multi-step reasoning, cross-document synthesis, or tool-based workflows, maintain or enhance prompts that include planning, reflection, and verification steps.
|
- For complex tasks, like multistep reasoning, cross-document synthesis, or tool-based workflows, maintain or enhance prompts that include planning, reflection, and verification steps.
|
||||||
|
|
||||||
- In multi-Agent orchestration systems, delegate simple subtasks to sub-Agents using smaller, faster models, and reserve more powerful models for the lead Agent to handle complexity and uncertainty.
|
- In multi-Agent orchestration systems, delegate simple subtasks to sub-Agents using smaller, faster models, and reserve more powerful models for the lead Agent to handle complexity and uncertainty.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -48,14 +48,14 @@ You start an AI conversation by creating an assistant.
|
||||||
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||||
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
||||||
- If you are uncertain about the logic behind **Variable**, leave it *as-is*.
|
- If you are uncertain about the logic behind **Variable**, leave it *as-is*.
|
||||||
- As of v0.21.1, if you add custom variables here, the only way you can pass in their values is to call:
|
- As of v0.17.2, if you add custom variables here, the only way you can pass in their values is to call:
|
||||||
- HTTP method [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant), or
|
- HTTP method [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant), or
|
||||||
- Python method [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant).
|
- Python method [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||||
|
|
||||||
4. Update Model-specific Settings:
|
4. Update Model-specific Settings:
|
||||||
|
|
||||||
- In **Model**: you select the chat model. Though you have selected the default chat model in **System Model Settings**, RAGFlow allows you to choose an alternative chat model for your dialogue.
|
- In **Model**: you select the chat model. Though you have selected the default chat model in **System Model Settings**, RAGFlow allows you to choose an alternative chat model for your dialogue.
|
||||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
This parameter has three options:
|
This parameter has three options:
|
||||||
- **Improvise**: Produces more creative responses.
|
- **Improvise**: Produces more creative responses.
|
||||||
- **Precise**: (Default) Produces more conservative responses.
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
|
|
||||||
|
|
@ -58,7 +58,7 @@ The Auto-keyword or Auto-question values relate closely to the chunking size in
|
||||||
|---------------------------------------------------------------------|---------------------------------|----------------------------|----------------------------|
|
|---------------------------------------------------------------------|---------------------------------|----------------------------|----------------------------|
|
||||||
| Internal process guidance for employee handbook | Small, under 10 pages | 0 | 0 |
|
| Internal process guidance for employee handbook | Small, under 10 pages | 0 | 0 |
|
||||||
| Customer service FAQs | Medium, 10–100 pages | 3–7 | 1–3 |
|
| Customer service FAQs | Medium, 10–100 pages | 3–7 | 1–3 |
|
||||||
| Technical whitepapers: Development standards, protocol details | Large, over 100 pages | 2–4 | 1–2 |
|
| Technical white papers: Development standards, protocol details | Large, over 100 pages | 2–4 | 1–2 |
|
||||||
| Contracts / Regulations / Legal clause retrieval | Large, over 50 pages | 2–5 | 0–1 |
|
| Contracts / Regulations / Legal clause retrieval | Large, over 50 pages | 2–5 | 0–1 |
|
||||||
| Multi-repository layered new documents + old archive | Many | Adjust as appropriate |Adjust as appropriate |
|
| Multi-repository layered new documents + old archive | Many | Adjust as appropriate |Adjust as appropriate |
|
||||||
| Social media comment pool: multilingual & mixed spelling | Very large volume of short text | 8–12 | 0 |
|
| Social media comment pool: multilingual & mixed spelling | Very large volume of short text | 8–12 | 0 |
|
||||||
|
|
|
||||||
|
|
@ -59,7 +59,7 @@ You can also change a file's chunking method on the **Files** page.
|
||||||
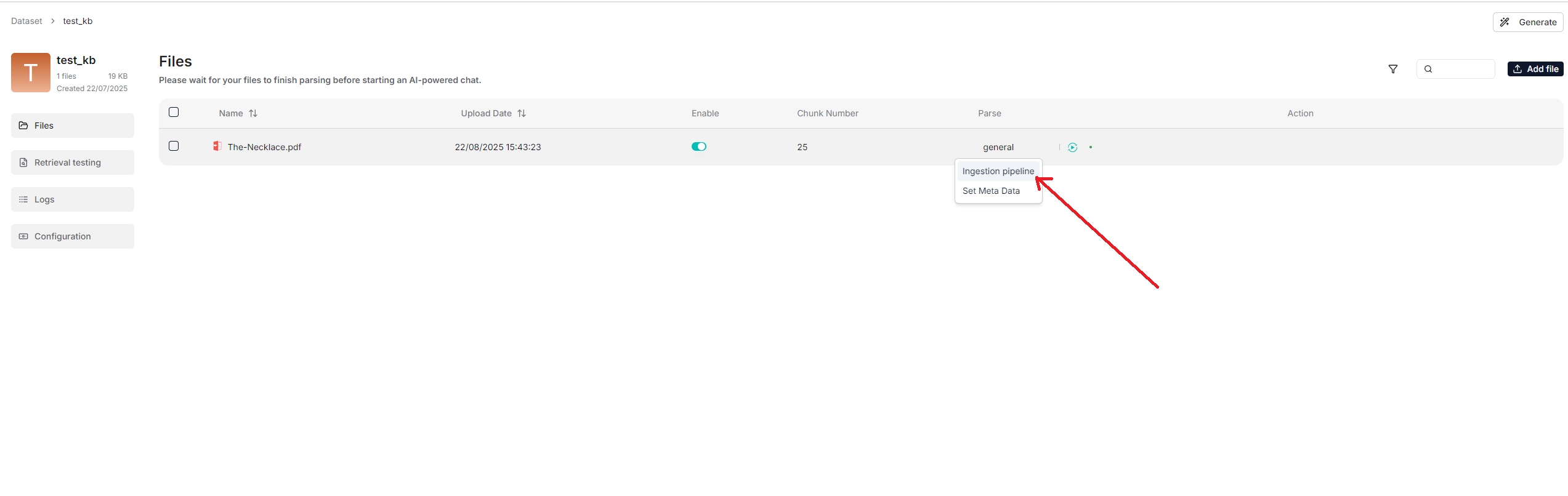
|

|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
<summary>From v0.21.1 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
||||||
|
|
||||||
To use a customized data pipeline:
|
To use a customized data pipeline:
|
||||||
|
|
||||||
|
|
@ -133,7 +133,7 @@ See [Run retrieval test](./run_retrieval_test.md) for details.
|
||||||
|
|
||||||
## Search for dataset
|
## Search for dataset
|
||||||
|
|
||||||
As of RAGFlow v0.21.1, the search feature is still in a rudimentary form, supporting only dataset search by name.
|
As of RAGFlow v0.22.0, the search feature is still in a rudimentary form, supporting only dataset search by name.
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -91,7 +91,7 @@ Nope. The knowledge graph does *not* update *until* you regenerate a knowledge g
|
||||||
|
|
||||||
### How to remove a generated knowledge graph?
|
### How to remove a generated knowledge graph?
|
||||||
|
|
||||||
On the **Configuration** page of your dataset, find the **Knoweledge graph** field and click the recycle bin button to the right of the field.
|
On the **Configuration** page of your dataset, find the **Knowledge graph** field and click the recycle bin button to the right of the field.
|
||||||
|
|
||||||
### Where is the created knowledge graph stored?
|
### Where is the created knowledge graph stored?
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -12,7 +12,7 @@ Convert complex Excel spreadsheets into HTML tables.
|
||||||
When using the **General** chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
When using the **General** chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
||||||
|
|
||||||
:::caution WARNING
|
:::caution WARNING
|
||||||
The feature is disabled by default. If your dataset contains spreadsheets with complex tables and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
The feature is disabled by default. If your dataset contains spreadsheets with complex tables, and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
## Scenarios
|
## Scenarios
|
||||||
|
|
|
||||||
|
|
@ -13,7 +13,7 @@ RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) is an enh
|
||||||
|
|
||||||
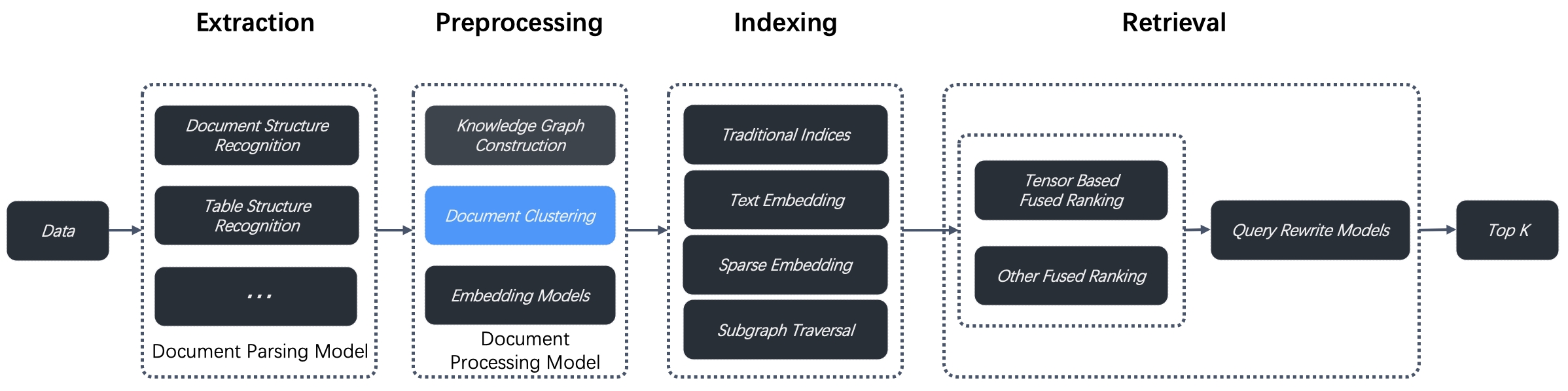
|

|
||||||
|
|
||||||
Our tests with this new approach demonstrate state-of-the-art (SOTA) results on question-answering tasks requiring complex, multi-step reasoning. By combining RAPTOR retrieval with our built-in chunking methods and/or other retrieval-augmented generation (RAG) approaches, you can further improve your question-answering accuracy.
|
Our tests with this new approach demonstrate state-of-the-art (SOTA) results on question-answering tasks requiring complex, multistep reasoning. By combining RAPTOR retrieval with our built-in chunking methods and/or other retrieval-augmented generation (RAG) approaches, you can further improve your question-answering accuracy.
|
||||||
|
|
||||||
:::danger WARNING
|
:::danger WARNING
|
||||||
Enabling RAPTOR requires significant memory, computational resources, and tokens.
|
Enabling RAPTOR requires significant memory, computational resources, and tokens.
|
||||||
|
|
@ -29,7 +29,7 @@ The recursive clustering and summarization capture a broad understanding (by the
|
||||||
|
|
||||||
## Scenarios
|
## Scenarios
|
||||||
|
|
||||||
For multi-hop question-answering tasks involving complex, multi-step reasoning, a semantic gap often exists between the question and its answer. As a result, searching with the question often fails to retrieve the relevant chunks that contribute to the correct answer. RAPTOR addresses this challenge by providing the chat model with richer and more context-aware and relevant chunks to summarize, enabling a holistic understanding without losing granular details.
|
For multi-hop question-answering tasks involving complex, multistep reasoning, a semantic gap often exists between the question and its answer. As a result, searching with the question often fails to retrieve the relevant chunks that contribute to the correct answer. RAPTOR addresses this challenge by providing the chat model with richer and more context-aware and relevant chunks to summarize, enabling a holistic understanding without losing granular details.
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
Knowledge graphs can also be used for multi-hop question-answering tasks. See [Construct knowledge graph](./construct_knowledge_graph.md) for details. You may use either approach or both, but ensure you understand the memory, computational, and token costs involved.
|
Knowledge graphs can also be used for multi-hop question-answering tasks. See [Construct knowledge graph](./construct_knowledge_graph.md) for details. You may use either approach or both, but ensure you understand the memory, computational, and token costs involved.
|
||||||
|
|
|
||||||
|
|
@ -23,7 +23,7 @@ RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper
|
||||||
- **Laws**
|
- **Laws**
|
||||||
- **Presentation**
|
- **Presentation**
|
||||||
- **One**
|
- **One**
|
||||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default img2txt model under **Set default models** on the **Model providers** page.
|
- To use a third-party visual model for parsing PDFs, ensure you have set a default VLM under **Set default models** on the **Model providers** page.
|
||||||
|
|
||||||
## Quickstart
|
## Quickstart
|
||||||
|
|
||||||
|
|
@ -39,7 +39,7 @@ RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper
|
||||||
- [Docling](https://github.com/docling-project/docling): (Experimental) An open-source document processing tool for gen AI.
|
- [Docling](https://github.com/docling-project/docling): (Experimental) An open-source document processing tool for gen AI.
|
||||||
- A third-party visual model from a specific model provider.
|
- A third-party visual model from a specific model provider.
|
||||||
|
|
||||||
:::danger IMPORTANG
|
:::danger IMPORTANT
|
||||||
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a client for MinerU, calling it to parse documents, reading the output files, and ingesting the parsed content. To use this feature, follow these steps:
|
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a client for MinerU, calling it to parse documents, reading the output files, and ingesting the parsed content. To use this feature, follow these steps:
|
||||||
|
|
||||||
1. Prepare MinerU:
|
1. Prepare MinerU:
|
||||||
|
|
@ -90,7 +90,7 @@ MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Restart the ragflow-server.
|
3. Restart the ragflow-server.
|
||||||
4. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and slect **MinerU** in **PDF parser**.
|
4. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and select **MinerU** in **PDF parser**.
|
||||||
5. If you use a custom ingestion pipeline instead, you must also complete the first three steps before selecting **MinerU** in the **Parsing method** section of the **Parser** component.
|
5. If you use a custom ingestion pipeline instead, you must also complete the first three steps before selecting **MinerU** in the **Parsing method** section of the **Parser** component.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
|
@ -102,7 +102,7 @@ Third-party visual models are marked **Experimental**, because we have not fully
|
||||||
|
|
||||||
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
||||||
|
|
||||||
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance img2txt model depending on your needs and hardware capabilities.
|
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance VLM depending on your needs and hardware capabilities.
|
||||||
|
|
||||||
### Can I select a visual model to parse my DOCX files?
|
### Can I select a visual model to parse my DOCX files?
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
---
|
---
|
||||||
sidebar_position: -7
|
sidebar_position: -7
|
||||||
slug: /set_metada
|
slug: /set_metadata
|
||||||
---
|
---
|
||||||
|
|
||||||
# Set metadata
|
# Set metadata
|
||||||
|
|
|
||||||
|
|
@ -73,7 +73,7 @@ Creating a tag set is *not* for once and for all. Oftentimes, you may find it ne
|
||||||
### Update tag set in tag frequency table
|
### Update tag set in tag frequency table
|
||||||
|
|
||||||
1. Navigate to the **Configuration** page in your tag set.
|
1. Navigate to the **Configuration** page in your tag set.
|
||||||
2. Click the **Table** tab under **Tag view** to view the tag frequncy table, where you can update tag names or delete tags.
|
2. Click the **Table** tab under **Tag view** to view the tag frequency table, where you can update tag names or delete tags.
|
||||||
|
|
||||||
:::danger IMPORTANT
|
:::danger IMPORTANT
|
||||||
When a tag set is updated, you must re-parse the documents in your dataset so that their tags can be updated accordingly.
|
When a tag set is updated, you must re-parse the documents in your dataset so that their tags can be updated accordingly.
|
||||||
|
|
|
||||||
|
|
@ -87,4 +87,4 @@ RAGFlow's file management allows you to download an uploaded file:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
> As of RAGFlow v0.21.1, bulk download is not supported, nor can you download an entire folder.
|
> As of RAGFlow v0.22.0, bulk download is not supported, nor can you download an entire folder.
|
||||||
|
|
|
||||||
|
|
@ -46,7 +46,7 @@ The Admin CLI and Admin Service form a client-server architectural suite for RAG
|
||||||
2. Install ragflow-cli.
|
2. Install ragflow-cli.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pip install ragflow-cli==0.21.1
|
pip install ragflow-cli==0.22.0
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Launch the CLI client:
|
3. Launch the CLI client:
|
||||||
|
|
|
||||||
|
|
@ -89,7 +89,7 @@ Once the restore process is complete, you can start the RAGFlow services on your
|
||||||
docker-compose -f docker/docker-compose.yml up -d
|
docker-compose -f docker/docker-compose.yml up -d
|
||||||
```
|
```
|
||||||
|
|
||||||
**Note:** If you already have build an service by docker-compose before, you may need to backup your data for target machine like this guide above and run like:
|
**Note:** If you already have built a service by docker-compose before, you may need to backup your data for target machine like this guide above and run like:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Please backup by `sh docker/migration.sh backup backup_dir_name` before you do the following line.
|
# Please backup by `sh docker/migration.sh backup backup_dir_name` before you do the following line.
|
||||||
|
|
|
||||||
|
|
@ -5,7 +5,7 @@ slug: /join_or_leave_team
|
||||||
|
|
||||||
# Join or leave a team
|
# Join or leave a team
|
||||||
|
|
||||||
Accept an invite to join a team, decline an invite, or leave a team.
|
Accept an invitation to join a team, decline an invitation, or leave a team.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -18,7 +18,7 @@ RAGFlow ships with a built-in [Langfuse](https://langfuse.com) integration so th
|
||||||
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
||||||
|
|
||||||
:::info NOTE
|
:::info NOTE
|
||||||
• RAGFlow **≥ 0.21.1** (contains the Langfuse connector)
|
• RAGFlow **≥ 0.18.0** (contains the Langfuse connector)
|
||||||
• A Langfuse workspace (cloud or self-hosted) with a _Project Public Key_ and _Secret Key_
|
• A Langfuse workspace (cloud or self-hosted) with a _Project Public Key_ and _Secret Key_
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -48,16 +48,16 @@ To upgrade RAGFlow, you must upgrade **both** your code **and** your Docker imag
|
||||||
git clone https://github.com/infiniflow/ragflow.git
|
git clone https://github.com/infiniflow/ragflow.git
|
||||||
```
|
```
|
||||||
|
|
||||||
2. Switch to the latest, officially published release, e.g., `v0.21.1`:
|
2. Switch to the latest, officially published release, e.g., `v0.22.0`:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
git checkout -f v0.21.1
|
git checkout -f v0.22.0
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Update **ragflow/docker/.env**:
|
3. Update **ragflow/docker/.env**:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1
|
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.0
|
||||||
```
|
```
|
||||||
|
|
||||||
4. Update the RAGFlow image and restart RAGFlow:
|
4. Update the RAGFlow image and restart RAGFlow:
|
||||||
|
|
@ -78,10 +78,10 @@ No, you do not need to. Upgrading RAGFlow in itself will *not* remove your uploa
|
||||||
1. From an environment with Internet access, pull the required Docker image.
|
1. From an environment with Internet access, pull the required Docker image.
|
||||||
2. Save the Docker image to a **.tar** file.
|
2. Save the Docker image to a **.tar** file.
|
||||||
```bash
|
```bash
|
||||||
docker save -o ragflow.v0.21.1.tar infiniflow/ragflow:v0.21.1
|
docker save -o ragflow.v0.22.0.tar infiniflow/ragflow:v0.22.0
|
||||||
```
|
```
|
||||||
3. Copy the **.tar** file to the target server.
|
3. Copy the **.tar** file to the target server.
|
||||||
4. Load the **.tar** file into Docker:
|
4. Load the **.tar** file into Docker:
|
||||||
```bash
|
```bash
|
||||||
docker load -i ragflow.v0.21.1.tar
|
docker load -i ragflow.v0.22.0.tar
|
||||||
```
|
```
|
||||||
|
|
|
||||||
|
|
@ -44,7 +44,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||||
|
|
||||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||||
|
|
||||||
RAGFlow v0.21.1 uses Elasticsearch or [Infinity](https://github.com/infiniflow/infinity) for multiple recall. Setting the value of `vm.max_map_count` correctly is crucial to the proper functioning of the Elasticsearch component.
|
RAGFlow v0.22.0 uses Elasticsearch or [Infinity](https://github.com/infiniflow/infinity) for multiple recall. Setting the value of `vm.max_map_count` correctly is crucial to the proper functioning of the Elasticsearch component.
|
||||||
|
|
||||||
<Tabs
|
<Tabs
|
||||||
defaultValue="linux"
|
defaultValue="linux"
|
||||||
|
|
@ -184,7 +184,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||||
```bash
|
```bash
|
||||||
$ git clone https://github.com/infiniflow/ragflow.git
|
$ git clone https://github.com/infiniflow/ragflow.git
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
$ git checkout -f v0.21.1
|
$ git checkout -f v0.22.0
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Use the pre-built Docker images and start up the server:
|
3. Use the pre-built Docker images and start up the server:
|
||||||
|
|
@ -200,7 +200,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||||
| ------------------- | --------------- | ------------------------ |
|
| ------------------- | --------------- | ------------------------ |
|
||||||
| v0.21.1 | ≈2 | Stable release |
|
| v0.22.0 | ≈2 | Stable release |
|
||||||
| nightly | ≈2 | _Unstable_ nightly build |
|
| nightly | ≈2 | _Unstable_ nightly build |
|
||||||
|
|
||||||
```mdx-code-block
|
```mdx-code-block
|
||||||
|
|
|
||||||
|
|
@ -19,7 +19,7 @@ import TOCInline from '@theme/TOCInline';
|
||||||
|
|
||||||
### Cross-language search
|
### Cross-language search
|
||||||
|
|
||||||
Cross-language search (also known as cross-lingual retrieval) is a feature introduced in version 0.21.1. It enables users to submit queries in one language (for example, English) and retrieve relevant documents written in other languages such as Chinese or Spanish. This feature is enabled by the system’s default chat model, which translates queries to ensure accurate matching of semantic meaning across languages.
|
Cross-language search (also known as cross-lingual retrieval) is a feature introduced in version 0.19.0. It enables users to submit queries in one language (for example, English) and retrieve relevant documents written in other languages such as Chinese or Spanish. This feature is enabled by the system’s default chat model, which translates queries to ensure accurate matching of semantic meaning across languages.
|
||||||
|
|
||||||
By enabling cross-language search, users can effortlessly access a broader range of information regardless of language barriers, significantly enhancing the system’s usability and inclusiveness.
|
By enabling cross-language search, users can effortlessly access a broader range of information regardless of language barriers, significantly enhancing the system’s usability and inclusiveness.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -56,7 +56,7 @@ env:
|
||||||
ragflow:
|
ragflow:
|
||||||
image:
|
image:
|
||||||
repository: infiniflow/ragflow
|
repository: infiniflow/ragflow
|
||||||
tag: v0.21.1-slim
|
tag: v0.22.0
|
||||||
pullPolicy: IfNotPresent
|
pullPolicy: IfNotPresent
|
||||||
pullSecrets: []
|
pullSecrets: []
|
||||||
# Optional service configuration overrides
|
# Optional service configuration overrides
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
[project]
|
[project]
|
||||||
name = "ragflow"
|
name = "ragflow"
|
||||||
version = "0.21.1"
|
version = "0.22.0"
|
||||||
description = "[RAGFlow](https://ragflow.io/) is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data."
|
description = "[RAGFlow](https://ragflow.io/) is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data."
|
||||||
authors = [{ name = "Zhichang Yu", email = "yuzhichang@gmail.com" }]
|
authors = [{ name = "Zhichang Yu", email = "yuzhichang@gmail.com" }]
|
||||||
license-files = ["LICENSE"]
|
license-files = ["LICENSE"]
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
[project]
|
[project]
|
||||||
name = "ragflow-sdk"
|
name = "ragflow-sdk"
|
||||||
version = "0.21.1"
|
version = "0.22.0"
|
||||||
description = "Python client sdk of [RAGFlow](https://github.com/infiniflow/ragflow). RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding."
|
description = "Python client sdk of [RAGFlow](https://github.com/infiniflow/ragflow). RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding."
|
||||||
authors = [{ name = "Zhichang Yu", email = "yuzhichang@gmail.com" }]
|
authors = [{ name = "Zhichang Yu", email = "yuzhichang@gmail.com" }]
|
||||||
license = { text = "Apache License, Version 2.0" }
|
license = { text = "Apache License, Version 2.0" }
|
||||||
|
|
|
||||||
2
sdk/python/uv.lock
generated
2
sdk/python/uv.lock
generated
|
|
@ -353,7 +353,7 @@ wheels = [
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "ragflow-sdk"
|
name = "ragflow-sdk"
|
||||||
version = "0.21.1"
|
version = "0.22.0"
|
||||||
source = { virtual = "." }
|
source = { virtual = "." }
|
||||||
dependencies = [
|
dependencies = [
|
||||||
{ name = "beartype" },
|
{ name = "beartype" },
|
||||||
|
|
|
||||||
2
uv.lock
generated
2
uv.lock
generated
|
|
@ -5196,7 +5196,7 @@ wheels = [
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "ragflow"
|
name = "ragflow"
|
||||||
version = "0.21.1"
|
version = "0.22.0"
|
||||||
source = { virtual = "." }
|
source = { virtual = "." }
|
||||||
dependencies = [
|
dependencies = [
|
||||||
{ name = "akshare" },
|
{ name = "akshare" },
|
||||||
|
|
|
||||||
Loading…
Add table
Reference in a new issue