Merge branch 'main' of github.com:infiniflow/ragflow into feature/1124
This commit is contained in:
commit
1f5e964a1e
277 changed files with 3199 additions and 12561 deletions
2
.github/workflows/tests.yml
vendored
2
.github/workflows/tests.yml
vendored
|
|
@ -31,7 +31,7 @@ jobs:
|
|||
name: ragflow_tests
|
||||
# https://docs.github.com/en/actions/using-jobs/using-conditions-to-control-job-execution
|
||||
# https://github.com/orgs/community/discussions/26261
|
||||
if: ${{ github.event_name != 'pull_request_target' || contains(github.event.pull_request.labels.*.name, 'ci') }}
|
||||
if: ${{ github.event_name != 'pull_request_target' || (contains(github.event.pull_request.labels.*.name, 'ci') && github.event.pull_request.mergeable == true) }}
|
||||
runs-on: [ "self-hosted", "ragflow-test" ]
|
||||
steps:
|
||||
# https://github.com/hmarr/debug-action
|
||||
|
|
|
|||
|
|
@ -281,6 +281,7 @@ class Canvas(Graph):
|
|||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
self.variables = {}
|
||||
super().__init__(dsl, tenant_id, task_id)
|
||||
|
||||
def load(self):
|
||||
|
|
@ -295,6 +296,10 @@ class Canvas(Graph):
|
|||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
if "variables" in self.dsl:
|
||||
self.variables = self.dsl["variables"]
|
||||
else:
|
||||
self.variables = {}
|
||||
|
||||
self.retrieval = self.dsl["retrieval"]
|
||||
self.memory = self.dsl.get("memory", [])
|
||||
|
|
@ -311,8 +316,9 @@ class Canvas(Graph):
|
|||
self.history = []
|
||||
self.retrieval = []
|
||||
self.memory = []
|
||||
print(self.variables)
|
||||
for k in self.globals.keys():
|
||||
if k.startswith("sys.") or k.startswith("env."):
|
||||
if k.startswith("sys."):
|
||||
if isinstance(self.globals[k], str):
|
||||
self.globals[k] = ""
|
||||
elif isinstance(self.globals[k], int):
|
||||
|
|
@ -325,6 +331,29 @@ class Canvas(Graph):
|
|||
self.globals[k] = {}
|
||||
else:
|
||||
self.globals[k] = None
|
||||
if k.startswith("env."):
|
||||
key = k[4:]
|
||||
if key in self.variables:
|
||||
variable = self.variables[key]
|
||||
if variable["value"]:
|
||||
self.globals[k] = variable["value"]
|
||||
else:
|
||||
if variable["type"] == "string":
|
||||
self.globals[k] = ""
|
||||
elif variable["type"] == "number":
|
||||
self.globals[k] = 0
|
||||
elif variable["type"] == "boolean":
|
||||
self.globals[k] = False
|
||||
elif variable["type"] == "object":
|
||||
self.globals[k] = {}
|
||||
elif variable["type"].startswith("array"):
|
||||
self.globals[k] = []
|
||||
else:
|
||||
self.globals[k] = ""
|
||||
else:
|
||||
self.globals[k] = ""
|
||||
print(self.globals)
|
||||
|
||||
|
||||
async def run(self, **kwargs):
|
||||
st = time.perf_counter()
|
||||
|
|
@ -473,7 +502,7 @@ class Canvas(Graph):
|
|||
else:
|
||||
self.error = cpn_obj.error()
|
||||
|
||||
if cpn_obj.component_name.lower() != "iteration":
|
||||
if cpn_obj.component_name.lower() not in ("iteration","loop"):
|
||||
if isinstance(cpn_obj.output("content"), partial):
|
||||
if self.error:
|
||||
cpn_obj.set_output("content", None)
|
||||
|
|
@ -498,14 +527,16 @@ class Canvas(Graph):
|
|||
for cpn_id in cpn_ids:
|
||||
_append_path(cpn_id)
|
||||
|
||||
if cpn_obj.component_name.lower() == "iterationitem" and cpn_obj.end():
|
||||
if cpn_obj.component_name.lower() in ("iterationitem","loopitem") and cpn_obj.end():
|
||||
iter = cpn_obj.get_parent()
|
||||
yield _node_finished(iter)
|
||||
_extend_path(self.get_component(cpn["parent_id"])["downstream"])
|
||||
elif cpn_obj.component_name.lower() in ["categorize", "switch"]:
|
||||
_extend_path(cpn_obj.output("_next"))
|
||||
elif cpn_obj.component_name.lower() == "iteration":
|
||||
elif cpn_obj.component_name.lower() in ("iteration", "loop"):
|
||||
_append_path(cpn_obj.get_start())
|
||||
elif cpn_obj.component_name.lower() == "exitloop" and cpn_obj.get_parent().component_name.lower() == "loop":
|
||||
_extend_path(self.get_component(cpn["parent_id"])["downstream"])
|
||||
elif not cpn["downstream"] and cpn_obj.get_parent():
|
||||
_append_path(cpn_obj.get_parent().get_start())
|
||||
else:
|
||||
|
|
|
|||
|
|
@ -13,6 +13,7 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
|
|
@ -29,7 +30,7 @@ from api.db.services.tenant_llm_service import TenantLLMService
|
|||
from api.db.services.mcp_server_service import MCPServerService
|
||||
from common.connection_utils import timeout
|
||||
from rag.prompts.generator import next_step, COMPLETE_TASK, analyze_task, \
|
||||
citation_prompt, reflect, rank_memories, kb_prompt, citation_plus, full_question, message_fit_in
|
||||
citation_prompt, reflect, rank_memories, kb_prompt, citation_plus, full_question, message_fit_in, structured_output_prompt
|
||||
from common.mcp_tool_call_conn import MCPToolCallSession, mcp_tool_metadata_to_openai_tool
|
||||
from agent.component.llm import LLMParam, LLM
|
||||
|
||||
|
|
@ -137,6 +138,29 @@ class Agent(LLM, ToolBase):
|
|||
res.update(cpn.get_input_form())
|
||||
return res
|
||||
|
||||
def _get_output_schema(self):
|
||||
try:
|
||||
cand = self._param.outputs.get("structured")
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
if isinstance(cand, dict):
|
||||
if isinstance(cand.get("properties"), dict) and len(cand["properties"]) > 0:
|
||||
return cand
|
||||
for k in ("schema", "structured"):
|
||||
if isinstance(cand.get(k), dict) and isinstance(cand[k].get("properties"), dict) and len(cand[k]["properties"]) > 0:
|
||||
return cand[k]
|
||||
|
||||
return None
|
||||
|
||||
def _force_format_to_schema(self, text: str, schema_prompt: str) -> str:
|
||||
fmt_msgs = [
|
||||
{"role": "system", "content": schema_prompt + "\nIMPORTANT: Output ONLY valid JSON. No markdown, no extra text."},
|
||||
{"role": "user", "content": text},
|
||||
]
|
||||
_, fmt_msgs = message_fit_in(fmt_msgs, int(self.chat_mdl.max_length * 0.97))
|
||||
return self._generate(fmt_msgs)
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 20*60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
|
|
@ -160,17 +184,22 @@ class Agent(LLM, ToolBase):
|
|||
return LLM._invoke(self, **kwargs)
|
||||
|
||||
prompt, msg, user_defined_prompt = self._prepare_prompt_variables()
|
||||
output_schema = self._get_output_schema()
|
||||
schema_prompt = ""
|
||||
if output_schema:
|
||||
schema = json.dumps(output_schema, ensure_ascii=False, indent=2)
|
||||
schema_prompt = structured_output_prompt(schema)
|
||||
|
||||
downstreams = self._canvas.get_component(self._id)["downstream"] if self._canvas.get_component(self._id) else []
|
||||
ex = self.exception_handler()
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]):
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]) and not output_schema:
|
||||
self.set_output("content", partial(self.stream_output_with_tools, prompt, msg, user_defined_prompt))
|
||||
return
|
||||
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
use_tools = []
|
||||
ans = ""
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt):
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt,schema_prompt=schema_prompt):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
return
|
||||
ans += delta_ans
|
||||
|
|
@ -183,6 +212,28 @@ class Agent(LLM, ToolBase):
|
|||
self.set_output("_ERROR", ans)
|
||||
return
|
||||
|
||||
if output_schema:
|
||||
error = ""
|
||||
for _ in range(self._param.max_retries + 1):
|
||||
try:
|
||||
def clean_formated_answer(ans: str) -> str:
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*```json", "", ans, flags=re.DOTALL)
|
||||
return re.sub(r"```\n*$", "", ans, flags=re.DOTALL)
|
||||
obj = json_repair.loads(clean_formated_answer(ans))
|
||||
self.set_output("structured", obj)
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
return obj
|
||||
except Exception:
|
||||
error = "The answer cannot be parsed as JSON"
|
||||
ans = self._force_format_to_schema(ans, schema_prompt)
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
continue
|
||||
|
||||
self.set_output("_ERROR", error)
|
||||
return
|
||||
|
||||
self.set_output("content", ans)
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
|
|
@ -219,7 +270,7 @@ class Agent(LLM, ToolBase):
|
|||
]):
|
||||
yield delta_ans
|
||||
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}):
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}, schema_prompt: str = ""):
|
||||
token_count = 0
|
||||
tool_metas = self.tool_meta
|
||||
hist = deepcopy(history)
|
||||
|
|
@ -256,9 +307,13 @@ class Agent(LLM, ToolBase):
|
|||
def complete():
|
||||
nonlocal hist
|
||||
need2cite = self._param.cite and self._canvas.get_reference()["chunks"] and self._id.find("-->") < 0
|
||||
if schema_prompt:
|
||||
need2cite = False
|
||||
cited = False
|
||||
if hist[0]["role"] == "system" and need2cite:
|
||||
if len(hist) < 7:
|
||||
if hist and hist[0]["role"] == "system":
|
||||
if schema_prompt:
|
||||
hist[0]["content"] += "\n" + schema_prompt
|
||||
if need2cite and len(hist) < 7:
|
||||
hist[0]["content"] += citation_prompt()
|
||||
cited = True
|
||||
yield "", token_count
|
||||
|
|
@ -369,7 +424,7 @@ Respond immediately with your final comprehensive answer.
|
|||
"""
|
||||
for k in self._param.outputs.keys():
|
||||
self._param.outputs[k]["value"] = None
|
||||
|
||||
|
||||
for k, cpn in self.tools.items():
|
||||
if hasattr(cpn, "reset") and callable(cpn.reset):
|
||||
cpn.reset()
|
||||
|
|
|
|||
32
agent/component/exit_loop.py
Normal file
32
agent/component/exit_loop.py
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class ExitLoopParam(ComponentParamBase, ABC):
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
|
||||
class ExitLoop(ComponentBase, ABC):
|
||||
component_name = "ExitLoop"
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
pass
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return ""
|
||||
|
|
@ -222,7 +222,7 @@ class LLM(ComponentBase):
|
|||
output_structure = self._param.outputs['structured']
|
||||
except Exception:
|
||||
pass
|
||||
if output_structure and isinstance(output_structure, dict) and output_structure.get("properties"):
|
||||
if output_structure and isinstance(output_structure, dict) and output_structure.get("properties") and len(output_structure["properties"]) > 0:
|
||||
schema=json.dumps(output_structure, ensure_ascii=False, indent=2)
|
||||
prompt += structured_output_prompt(schema)
|
||||
for _ in range(self._param.max_retries+1):
|
||||
|
|
|
|||
80
agent/component/loop.py
Normal file
80
agent/component/loop.py
Normal file
|
|
@ -0,0 +1,80 @@
|
|||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class LoopParam(ComponentParamBase):
|
||||
"""
|
||||
Define the Loop component parameters.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.loop_variables = []
|
||||
self.loop_termination_condition=[]
|
||||
self.maximum_loop_count = 0
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {
|
||||
"items": {
|
||||
"type": "json",
|
||||
"name": "Items"
|
||||
}
|
||||
}
|
||||
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
|
||||
class Loop(ComponentBase, ABC):
|
||||
component_name = "Loop"
|
||||
|
||||
def get_start(self):
|
||||
for cid in self._canvas.components.keys():
|
||||
if self._canvas.get_component(cid)["obj"].component_name.lower() != "loopitem":
|
||||
continue
|
||||
if self._canvas.get_component(cid)["parent_id"] == self._id:
|
||||
return cid
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("Loop processing"):
|
||||
return
|
||||
|
||||
for item in self._param.loop_variables:
|
||||
if any([not item.get("variable"), not item.get("input_mode"), not item.get("value"),not item.get("type")]):
|
||||
assert "Loop Variable is not complete."
|
||||
if item["input_mode"]=="variable":
|
||||
self.set_output(item["variable"],self._canvas.get_variable_value(item["value"]))
|
||||
elif item["input_mode"]=="constant":
|
||||
self.set_output(item["variable"],item["value"])
|
||||
else:
|
||||
if item["type"] == "number":
|
||||
self.set_output(item["variable"], 0)
|
||||
elif item["type"] == "string":
|
||||
self.set_output(item["variable"], "")
|
||||
elif item["type"] == "boolean":
|
||||
self.set_output(item["variable"], False)
|
||||
elif item["type"].startswith("object"):
|
||||
self.set_output(item["variable"], {})
|
||||
elif item["type"].startswith("array"):
|
||||
self.set_output(item["variable"], [])
|
||||
else:
|
||||
self.set_output(item["variable"], "")
|
||||
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Loop from canvas."
|
||||
163
agent/component/loopitem.py
Normal file
163
agent/component/loopitem.py
Normal file
|
|
@ -0,0 +1,163 @@
|
|||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class LoopItemParam(ComponentParamBase):
|
||||
"""
|
||||
Define the LoopItem component parameters.
|
||||
"""
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
class LoopItem(ComponentBase, ABC):
|
||||
component_name = "LoopItem"
|
||||
|
||||
def __init__(self, canvas, id, param: ComponentParamBase):
|
||||
super().__init__(canvas, id, param)
|
||||
self._idx = 0
|
||||
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("LoopItem processing"):
|
||||
return
|
||||
parent = self.get_parent()
|
||||
maximum_loop_count = parent._param.maximum_loop_count
|
||||
if self._idx >= maximum_loop_count:
|
||||
self._idx = -1
|
||||
return
|
||||
if self._idx > 0:
|
||||
if self.check_if_canceled("LoopItem processing"):
|
||||
return
|
||||
self._idx += 1
|
||||
|
||||
def evaluate_condition(self,var, operator, value):
|
||||
if isinstance(var, str):
|
||||
if operator == "contains":
|
||||
return value in var
|
||||
elif operator == "not contains":
|
||||
return value not in var
|
||||
elif operator == "start with":
|
||||
return var.startswith(value)
|
||||
elif operator == "end with":
|
||||
return var.endswith(value)
|
||||
elif operator == "is":
|
||||
return var == value
|
||||
elif operator == "is not":
|
||||
return var != value
|
||||
elif operator == "empty":
|
||||
return var == ""
|
||||
elif operator == "not empty":
|
||||
return var != ""
|
||||
|
||||
elif isinstance(var, (int, float)):
|
||||
if operator == "=":
|
||||
return var == value
|
||||
elif operator == "≠":
|
||||
return var != value
|
||||
elif operator == ">":
|
||||
return var > value
|
||||
elif operator == "<":
|
||||
return var < value
|
||||
elif operator == "≥":
|
||||
return var >= value
|
||||
elif operator == "≤":
|
||||
return var <= value
|
||||
elif operator == "empty":
|
||||
return var is None
|
||||
elif operator == "not empty":
|
||||
return var is not None
|
||||
|
||||
elif isinstance(var, bool):
|
||||
if operator == "is":
|
||||
return var is value
|
||||
elif operator == "is not":
|
||||
return var is not value
|
||||
elif operator == "empty":
|
||||
return var is None
|
||||
elif operator == "not empty":
|
||||
return var is not None
|
||||
|
||||
elif isinstance(var, dict):
|
||||
if operator == "empty":
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
|
||||
elif isinstance(var, list):
|
||||
if operator == "contains":
|
||||
return value in var
|
||||
elif operator == "not contains":
|
||||
return value not in var
|
||||
|
||||
elif operator == "is":
|
||||
return var == value
|
||||
elif operator == "is not":
|
||||
return var != value
|
||||
|
||||
elif operator == "empty":
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
|
||||
raise Exception(f"Invalid operator: {operator}")
|
||||
|
||||
def end(self):
|
||||
if self._idx == -1:
|
||||
return True
|
||||
parent = self.get_parent()
|
||||
logical_operator = parent._param.logical_operator if hasattr(parent._param, "logical_operator") else "and"
|
||||
conditions = []
|
||||
for item in parent._param.loop_termination_condition:
|
||||
if not item.get("variable") or not item.get("operator"):
|
||||
raise ValueError("Loop condition is incomplete.")
|
||||
var = self._canvas.get_variable_value(item["variable"])
|
||||
operator = item["operator"]
|
||||
input_mode = item.get("input_mode", "constant")
|
||||
|
||||
if input_mode == "variable":
|
||||
value = self._canvas.get_variable_value(item.get("value", ""))
|
||||
elif input_mode == "constant":
|
||||
value = item.get("value", "")
|
||||
else:
|
||||
raise ValueError("Invalid input mode.")
|
||||
conditions.append(self.evaluate_condition(var, operator, value))
|
||||
should_end = (
|
||||
all(conditions) if logical_operator == "and"
|
||||
else any(conditions) if logical_operator == "or"
|
||||
else None
|
||||
)
|
||||
if should_end is None:
|
||||
raise ValueError("Invalid logical operator,should be 'and' or 'or'.")
|
||||
|
||||
if should_end:
|
||||
self._idx = -1
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def next(self):
|
||||
if self._idx == -1:
|
||||
self._idx = 0
|
||||
else:
|
||||
self._idx += 1
|
||||
if self._idx >= len(self._items):
|
||||
self._idx = -1
|
||||
return False
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Next turn..."
|
||||
|
|
@ -28,8 +28,8 @@ from api.db import InputType
|
|||
from api.db.services.connector_service import ConnectorService, SyncLogsService
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, validate_request
|
||||
from common.constants import RetCode, TaskStatus
|
||||
from common.data_source.config import GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI, DocumentSource
|
||||
from common.data_source.google_util.constant import GOOGLE_DRIVE_WEB_OAUTH_POPUP_TEMPLATE, GOOGLE_SCOPES
|
||||
from common.data_source.config import GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI, GMAIL_WEB_OAUTH_REDIRECT_URI, DocumentSource
|
||||
from common.data_source.google_util.constant import GOOGLE_WEB_OAUTH_POPUP_TEMPLATE, GOOGLE_SCOPES
|
||||
from common.misc_utils import get_uuid
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from api.apps import login_required, current_user
|
||||
|
|
@ -122,12 +122,30 @@ GOOGLE_WEB_FLOW_RESULT_PREFIX = "google_drive_web_flow_result"
|
|||
WEB_FLOW_TTL_SECS = 15 * 60
|
||||
|
||||
|
||||
def _web_state_cache_key(flow_id: str) -> str:
|
||||
return f"{GOOGLE_WEB_FLOW_STATE_PREFIX}:{flow_id}"
|
||||
def _web_state_cache_key(flow_id: str, source_type: str | None = None) -> str:
|
||||
"""Return Redis key for web OAuth state.
|
||||
|
||||
The default prefix keeps backward compatibility for Google Drive.
|
||||
When source_type == "gmail", a different prefix is used so that
|
||||
Drive/Gmail flows don't clash in Redis.
|
||||
"""
|
||||
if source_type == "gmail":
|
||||
prefix = "gmail_web_flow_state"
|
||||
else:
|
||||
prefix = GOOGLE_WEB_FLOW_STATE_PREFIX
|
||||
return f"{prefix}:{flow_id}"
|
||||
|
||||
|
||||
def _web_result_cache_key(flow_id: str) -> str:
|
||||
return f"{GOOGLE_WEB_FLOW_RESULT_PREFIX}:{flow_id}"
|
||||
def _web_result_cache_key(flow_id: str, source_type: str | None = None) -> str:
|
||||
"""Return Redis key for web OAuth result.
|
||||
|
||||
Mirrors _web_state_cache_key logic for result storage.
|
||||
"""
|
||||
if source_type == "gmail":
|
||||
prefix = "gmail_web_flow_result"
|
||||
else:
|
||||
prefix = GOOGLE_WEB_FLOW_RESULT_PREFIX
|
||||
return f"{prefix}:{flow_id}"
|
||||
|
||||
|
||||
def _load_credentials(payload: str | dict[str, Any]) -> dict[str, Any]:
|
||||
|
|
@ -146,19 +164,22 @@ def _get_web_client_config(credentials: dict[str, Any]) -> dict[str, Any]:
|
|||
return {"web": web_section}
|
||||
|
||||
|
||||
async def _render_web_oauth_popup(flow_id: str, success: bool, message: str):
|
||||
async def _render_web_oauth_popup(flow_id: str, success: bool, message: str, source="drive"):
|
||||
status = "success" if success else "error"
|
||||
auto_close = "window.close();" if success else ""
|
||||
escaped_message = escape(message)
|
||||
payload_json = json.dumps(
|
||||
{
|
||||
"type": "ragflow-google-drive-oauth",
|
||||
# TODO(google-oauth): include connector type (drive/gmail) in payload type if needed
|
||||
"type": f"ragflow-google-{source}-oauth",
|
||||
"status": status,
|
||||
"flowId": flow_id or "",
|
||||
"message": message,
|
||||
}
|
||||
)
|
||||
html = GOOGLE_DRIVE_WEB_OAUTH_POPUP_TEMPLATE.format(
|
||||
# TODO(google-oauth): title/heading/message may need to reflect drive/gmail based on cached type
|
||||
html = GOOGLE_WEB_OAUTH_POPUP_TEMPLATE.format(
|
||||
title=f"Google {source.capitalize()} Authorization",
|
||||
heading="Authorization complete" if success else "Authorization failed",
|
||||
message=escaped_message,
|
||||
payload_json=payload_json,
|
||||
|
|
@ -169,20 +190,33 @@ async def _render_web_oauth_popup(flow_id: str, success: bool, message: str):
|
|||
return response
|
||||
|
||||
|
||||
@manager.route("/google-drive/oauth/web/start", methods=["POST"]) # noqa: F821
|
||||
@manager.route("/google/oauth/web/start", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("credentials")
|
||||
async def start_google_drive_web_oauth():
|
||||
if not GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI:
|
||||
async def start_google_web_oauth():
|
||||
source = request.args.get("type", "google-drive")
|
||||
if source not in ("google-drive", "gmail"):
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message="Invalid Google OAuth type.")
|
||||
|
||||
if source == "gmail":
|
||||
redirect_uri = GMAIL_WEB_OAUTH_REDIRECT_URI
|
||||
scopes = GOOGLE_SCOPES[DocumentSource.GMAIL]
|
||||
else:
|
||||
redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI if source == "google-drive" else GMAIL_WEB_OAUTH_REDIRECT_URI
|
||||
scopes = GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE if source == "google-drive" else DocumentSource.GMAIL]
|
||||
|
||||
if not redirect_uri:
|
||||
return get_json_result(
|
||||
code=RetCode.SERVER_ERROR,
|
||||
message="Google Drive OAuth redirect URI is not configured on the server.",
|
||||
message="Google OAuth redirect URI is not configured on the server.",
|
||||
)
|
||||
|
||||
req = await request.json or {}
|
||||
raw_credentials = req.get("credentials", "")
|
||||
|
||||
try:
|
||||
credentials = _load_credentials(raw_credentials)
|
||||
print(credentials)
|
||||
except ValueError as exc:
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message=str(exc))
|
||||
|
||||
|
|
@ -199,8 +233,8 @@ async def start_google_drive_web_oauth():
|
|||
|
||||
flow_id = str(uuid.uuid4())
|
||||
try:
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE])
|
||||
flow.redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI
|
||||
flow = Flow.from_client_config(client_config, scopes=scopes)
|
||||
flow.redirect_uri = redirect_uri
|
||||
authorization_url, _ = flow.authorization_url(
|
||||
access_type="offline",
|
||||
include_granted_scopes="true",
|
||||
|
|
@ -219,7 +253,7 @@ async def start_google_drive_web_oauth():
|
|||
"client_config": client_config,
|
||||
"created_at": int(time.time()),
|
||||
}
|
||||
REDIS_CONN.set_obj(_web_state_cache_key(flow_id), cache_payload, WEB_FLOW_TTL_SECS)
|
||||
REDIS_CONN.set_obj(_web_state_cache_key(flow_id, source), cache_payload, WEB_FLOW_TTL_SECS)
|
||||
|
||||
return get_json_result(
|
||||
data={
|
||||
|
|
@ -230,60 +264,122 @@ async def start_google_drive_web_oauth():
|
|||
)
|
||||
|
||||
|
||||
@manager.route("/google-drive/oauth/web/callback", methods=["GET"]) # noqa: F821
|
||||
async def google_drive_web_oauth_callback():
|
||||
@manager.route("/gmail/oauth/web/callback", methods=["GET"]) # noqa: F821
|
||||
async def google_gmail_web_oauth_callback():
|
||||
state_id = request.args.get("state")
|
||||
error = request.args.get("error")
|
||||
source = "gmail"
|
||||
if source != 'gmail':
|
||||
return await _render_web_oauth_popup("", False, "Invalid Google OAuth type.", source)
|
||||
|
||||
error_description = request.args.get("error_description") or error
|
||||
|
||||
if not state_id:
|
||||
return await _render_web_oauth_popup("", False, "Missing OAuth state parameter.")
|
||||
return await _render_web_oauth_popup("", False, "Missing OAuth state parameter.", source)
|
||||
|
||||
state_cache = REDIS_CONN.get(_web_state_cache_key(state_id))
|
||||
state_cache = REDIS_CONN.get(_web_state_cache_key(state_id, source))
|
||||
if not state_cache:
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session expired. Please restart from the main window.")
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session expired. Please restart from the main window.", source)
|
||||
|
||||
state_obj = json.loads(state_cache)
|
||||
client_config = state_obj.get("client_config")
|
||||
if not client_config:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session was invalid. Please retry.")
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session was invalid. Please retry.", source)
|
||||
|
||||
if error:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
return await _render_web_oauth_popup(state_id, False, error_description or "Authorization was cancelled.")
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, error_description or "Authorization was cancelled.", source)
|
||||
|
||||
code = request.args.get("code")
|
||||
if not code:
|
||||
return await _render_web_oauth_popup(state_id, False, "Missing authorization code from Google.")
|
||||
return await _render_web_oauth_popup(state_id, False, "Missing authorization code from Google.", source)
|
||||
|
||||
try:
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE])
|
||||
flow.redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI
|
||||
# TODO(google-oauth): branch scopes/redirect_uri based on source_type (drive vs gmail)
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GMAIL])
|
||||
flow.redirect_uri = GMAIL_WEB_OAUTH_REDIRECT_URI
|
||||
flow.fetch_token(code=code)
|
||||
except Exception as exc: # pragma: no cover - defensive
|
||||
logging.exception("Failed to exchange Google OAuth code: %s", exc)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
return await _render_web_oauth_popup(state_id, False, "Failed to exchange tokens with Google. Please retry.")
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Failed to exchange tokens with Google. Please retry.", source)
|
||||
|
||||
creds_json = flow.credentials.to_json()
|
||||
result_payload = {
|
||||
"user_id": state_obj.get("user_id"),
|
||||
"credentials": creds_json,
|
||||
}
|
||||
REDIS_CONN.set_obj(_web_result_cache_key(state_id), result_payload, WEB_FLOW_TTL_SECS)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
REDIS_CONN.set_obj(_web_result_cache_key(state_id, source), result_payload, WEB_FLOW_TTL_SECS)
|
||||
|
||||
return await _render_web_oauth_popup(state_id, True, "Authorization completed successfully.")
|
||||
print("\n\n", _web_result_cache_key(state_id, source), "\n\n")
|
||||
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
|
||||
return await _render_web_oauth_popup(state_id, True, "Authorization completed successfully.", source)
|
||||
|
||||
|
||||
@manager.route("/google-drive/oauth/web/result", methods=["POST"]) # noqa: F821
|
||||
@manager.route("/google-drive/oauth/web/callback", methods=["GET"]) # noqa: F821
|
||||
async def google_drive_web_oauth_callback():
|
||||
state_id = request.args.get("state")
|
||||
error = request.args.get("error")
|
||||
source = "google-drive"
|
||||
if source not in ("google-drive", "gmail"):
|
||||
return await _render_web_oauth_popup("", False, "Invalid Google OAuth type.", source)
|
||||
|
||||
error_description = request.args.get("error_description") or error
|
||||
|
||||
if not state_id:
|
||||
return await _render_web_oauth_popup("", False, "Missing OAuth state parameter.", source)
|
||||
|
||||
state_cache = REDIS_CONN.get(_web_state_cache_key(state_id, source))
|
||||
if not state_cache:
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session expired. Please restart from the main window.", source)
|
||||
|
||||
state_obj = json.loads(state_cache)
|
||||
client_config = state_obj.get("client_config")
|
||||
if not client_config:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session was invalid. Please retry.", source)
|
||||
|
||||
if error:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, error_description or "Authorization was cancelled.", source)
|
||||
|
||||
code = request.args.get("code")
|
||||
if not code:
|
||||
return await _render_web_oauth_popup(state_id, False, "Missing authorization code from Google.", source)
|
||||
|
||||
try:
|
||||
# TODO(google-oauth): branch scopes/redirect_uri based on source_type (drive vs gmail)
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE])
|
||||
flow.redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI
|
||||
flow.fetch_token(code=code)
|
||||
except Exception as exc: # pragma: no cover - defensive
|
||||
logging.exception("Failed to exchange Google OAuth code: %s", exc)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Failed to exchange tokens with Google. Please retry.", source)
|
||||
|
||||
creds_json = flow.credentials.to_json()
|
||||
result_payload = {
|
||||
"user_id": state_obj.get("user_id"),
|
||||
"credentials": creds_json,
|
||||
}
|
||||
REDIS_CONN.set_obj(_web_result_cache_key(state_id, source), result_payload, WEB_FLOW_TTL_SECS)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
|
||||
return await _render_web_oauth_popup(state_id, True, "Authorization completed successfully.", source)
|
||||
|
||||
@manager.route("/google/oauth/web/result", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("flow_id")
|
||||
async def poll_google_drive_web_result():
|
||||
async def poll_google_web_result():
|
||||
req = await request.json or {}
|
||||
source = request.args.get("type")
|
||||
if source not in ("google-drive", "gmail"):
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message="Invalid Google OAuth type.")
|
||||
flow_id = req.get("flow_id")
|
||||
cache_raw = REDIS_CONN.get(_web_result_cache_key(flow_id))
|
||||
cache_raw = REDIS_CONN.get(_web_result_cache_key(flow_id, source))
|
||||
if not cache_raw:
|
||||
return get_json_result(code=RetCode.RUNNING, message="Authorization is still pending.")
|
||||
|
||||
|
|
@ -291,5 +387,5 @@ async def poll_google_drive_web_result():
|
|||
if result.get("user_id") != current_user.id:
|
||||
return get_json_result(code=RetCode.PERMISSION_ERROR, message="You are not allowed to access this authorization result.")
|
||||
|
||||
REDIS_CONN.delete(_web_result_cache_key(flow_id))
|
||||
REDIS_CONN.delete(_web_result_cache_key(flow_id, source))
|
||||
return get_json_result(data={"credentials": result.get("credentials")})
|
||||
|
|
|
|||
|
|
@ -31,7 +31,7 @@ from api.db.services.file_service import FileService
|
|||
from api.utils.api_utils import get_json_result
|
||||
from api.utils.file_utils import filename_type
|
||||
from common import settings
|
||||
|
||||
from common.constants import RetCode
|
||||
|
||||
@manager.route('/file/upload', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
|
|
@ -86,19 +86,19 @@ async def upload(tenant_id):
|
|||
pf_id = root_folder["id"]
|
||||
|
||||
if 'file' not in files:
|
||||
return get_json_result(data=False, message='No file part!', code=400)
|
||||
return get_json_result(data=False, message='No file part!', code=RetCode.BAD_REQUEST)
|
||||
file_objs = files.getlist('file')
|
||||
|
||||
for file_obj in file_objs:
|
||||
if file_obj.filename == '':
|
||||
return get_json_result(data=False, message='No selected file!', code=400)
|
||||
return get_json_result(data=False, message='No selected file!', code=RetCode.BAD_REQUEST)
|
||||
|
||||
file_res = []
|
||||
|
||||
try:
|
||||
e, pf_folder = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=404)
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=RetCode.NOT_FOUND)
|
||||
|
||||
for file_obj in file_objs:
|
||||
# Handle file path
|
||||
|
|
@ -114,13 +114,13 @@ async def upload(tenant_id):
|
|||
if file_len != len_id_list:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 1])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 1], file_obj_names,
|
||||
len_id_list)
|
||||
else:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 2])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 2], file_obj_names,
|
||||
len_id_list)
|
||||
|
||||
|
|
@ -202,7 +202,7 @@ async def create(tenant_id):
|
|||
|
||||
try:
|
||||
if not FileService.is_parent_folder_exist(pf_id):
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=400)
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=RetCode.BAD_REQUEST)
|
||||
if FileService.query(name=req["name"], parent_id=pf_id):
|
||||
return get_json_result(data=False, message="Duplicated folder name in the same folder.", code=409)
|
||||
|
||||
|
|
@ -306,13 +306,13 @@ def list_files(tenant_id):
|
|||
try:
|
||||
e, file = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
files, total = FileService.get_by_pf_id(tenant_id, pf_id, page_number, items_per_page, orderby, desc, keywords)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(pf_id)
|
||||
if not parent_folder:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
return get_json_result(data={"total": total, "files": files, "parent_folder": parent_folder.to_json()})
|
||||
except Exception as e:
|
||||
|
|
@ -392,7 +392,7 @@ def get_parent_folder():
|
|||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(file_id)
|
||||
return get_json_result(data={"parent_folder": parent_folder.to_json()})
|
||||
|
|
@ -439,7 +439,7 @@ def get_all_parent_folders(tenant_id):
|
|||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folders = FileService.get_all_parent_folders(file_id)
|
||||
parent_folders_res = [folder.to_json() for folder in parent_folders]
|
||||
|
|
@ -487,34 +487,34 @@ async def rm(tenant_id):
|
|||
for file_id in file_ids:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_id_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
for inner_file_id in file_id_list:
|
||||
e, file = FileService.get_by_id(inner_file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
FileService.delete_folder_by_pf_id(tenant_id, file_id)
|
||||
else:
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
if not FileService.delete(file):
|
||||
return get_json_result(message="Database error (File removal)!", code=500)
|
||||
return get_json_result(message="Database error (File removal)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(file_id)
|
||||
for inform in informs:
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(message="Database error (Document removal)!", code=500)
|
||||
return get_json_result(message="Database error (Document removal)!", code=RetCode.SERVER_ERROR)
|
||||
File2DocumentService.delete_by_file_id(file_id)
|
||||
|
||||
return get_json_result(data=True)
|
||||
|
|
@ -560,23 +560,23 @@ async def rename(tenant_id):
|
|||
try:
|
||||
e, file = FileService.get_by_id(req["file_id"])
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type != FileType.FOLDER.value and pathlib.Path(req["name"].lower()).suffix != pathlib.Path(
|
||||
file.name.lower()).suffix:
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=400)
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=RetCode.BAD_REQUEST)
|
||||
|
||||
for existing_file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
||||
if existing_file.name == req["name"]:
|
||||
return get_json_result(data=False, message="Duplicated file name in the same folder.", code=409)
|
||||
|
||||
if not FileService.update_by_id(req["file_id"], {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (File rename)!", code=500)
|
||||
return get_json_result(message="Database error (File rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(req["file_id"])
|
||||
if informs:
|
||||
if not DocumentService.update_by_id(informs[0].document_id, {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (Document rename)!", code=500)
|
||||
return get_json_result(message="Database error (Document rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
|
|
@ -606,13 +606,13 @@ async def get(tenant_id, file_id):
|
|||
description: File stream
|
||||
schema:
|
||||
type: file
|
||||
404:
|
||||
RetCode.NOT_FOUND:
|
||||
description: File not found
|
||||
"""
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
blob = settings.STORAGE_IMPL.get(file.parent_id, file.location)
|
||||
if not blob:
|
||||
|
|
@ -677,13 +677,13 @@ async def move(tenant_id):
|
|||
for file_id in file_ids:
|
||||
file = files_dict[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
fe, _ = FileService.get_by_id(parent_id)
|
||||
if not fe:
|
||||
return get_json_result(message="Parent Folder not found!", code=404)
|
||||
return get_json_result(message="Parent Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
FileService.move_file(file_ids, parent_id)
|
||||
return get_json_result(data=True)
|
||||
|
|
@ -705,7 +705,7 @@ async def convert(tenant_id):
|
|||
for file_id in file_ids:
|
||||
file = files_set[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
file_ids_list = [file_id]
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_ids_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
|
|
@ -716,13 +716,13 @@ async def convert(tenant_id):
|
|||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(
|
||||
message="Database error (Document removal)!", code=404)
|
||||
message="Database error (Document removal)!", code=RetCode.NOT_FOUND)
|
||||
File2DocumentService.delete_by_file_id(id)
|
||||
|
||||
# insert
|
||||
|
|
@ -730,11 +730,11 @@ async def convert(tenant_id):
|
|||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this knowledgebase!", code=404)
|
||||
message="Can't find this knowledgebase!", code=RetCode.NOT_FOUND)
|
||||
e, file = FileService.get_by_id(id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this file!", code=404)
|
||||
message="Can't find this file!", code=RetCode.NOT_FOUND)
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
|
|
|
|||
|
|
@ -121,8 +121,8 @@ async def login():
|
|||
response_data = user.to_json()
|
||||
user.access_token = get_uuid()
|
||||
login_user(user)
|
||||
user.update_time = (current_timestamp(),)
|
||||
user.update_date = (datetime_format(datetime.now()),)
|
||||
user.update_time = current_timestamp()
|
||||
user.update_date = datetime_format(datetime.now())
|
||||
user.save()
|
||||
msg = "Welcome back!"
|
||||
|
||||
|
|
@ -1002,8 +1002,8 @@ async def forget():
|
|||
# Auto login (reuse login flow)
|
||||
user.access_token = get_uuid()
|
||||
login_user(user)
|
||||
user.update_time = (current_timestamp(),)
|
||||
user.update_date = (datetime_format(datetime.now()),)
|
||||
user.update_time = current_timestamp()
|
||||
user.update_date = datetime_format(datetime.now())
|
||||
user.save()
|
||||
msg = "Password reset successful. Logged in."
|
||||
return construct_response(data=user.to_json(), auth=user.get_id(), message=msg)
|
||||
|
|
|
|||
|
|
@ -749,7 +749,7 @@ class Knowledgebase(DataBaseModel):
|
|||
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", default=ParserType.NAIVE.value, index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="Pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
pagerank = IntegerField(default=0, index=False)
|
||||
|
||||
graphrag_task_id = CharField(max_length=32, null=True, help_text="Graph RAG task ID", index=True)
|
||||
|
|
@ -774,7 +774,7 @@ class Document(DataBaseModel):
|
|||
kb_id = CharField(max_length=256, null=False, index=True)
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
source_type = CharField(max_length=128, null=False, default="local", help_text="where dose this document come from", index=True)
|
||||
type = CharField(max_length=32, null=False, help_text="file extension", index=True)
|
||||
created_by = CharField(max_length=32, null=False, help_text="who created it", index=True)
|
||||
|
|
|
|||
|
|
@ -214,9 +214,21 @@ class SyncLogsService(CommonService):
|
|||
err, doc_blob_pairs = FileService.upload_document(kb, files, tenant_id, src)
|
||||
errs.extend(err)
|
||||
|
||||
# Create a mapping from filename to metadata for later use
|
||||
metadata_map = {}
|
||||
for d in docs:
|
||||
if d.get("metadata"):
|
||||
filename = d["semantic_identifier"]+(f"{d['extension']}" if d["semantic_identifier"][::-1].find(d['extension'][::-1])<0 else "")
|
||||
metadata_map[filename] = d["metadata"]
|
||||
|
||||
kb_table_num_map = {}
|
||||
for doc, _ in doc_blob_pairs:
|
||||
doc_ids.append(doc["id"])
|
||||
|
||||
# Set metadata if available for this document
|
||||
if doc["name"] in metadata_map:
|
||||
DocumentService.update_by_id(doc["id"], {"meta_fields": metadata_map[doc["name"]]})
|
||||
|
||||
if not auto_parse or auto_parse == "0":
|
||||
continue
|
||||
DocumentService.run(tenant_id, doc, kb_table_num_map)
|
||||
|
|
|
|||
|
|
@ -923,7 +923,7 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
|||
ParserType.AUDIO.value: audio,
|
||||
ParserType.EMAIL.value: email
|
||||
}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text"}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text", "table_context_size": 0, "image_context_size": 0}
|
||||
exe = ThreadPoolExecutor(max_workers=12)
|
||||
threads = []
|
||||
doc_nm = {}
|
||||
|
|
|
|||
|
|
@ -313,6 +313,10 @@ def get_parser_config(chunk_method, parser_config):
|
|||
chunk_method = "naive"
|
||||
|
||||
# Define default configurations for each chunking method
|
||||
base_defaults = {
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
}
|
||||
key_mapping = {
|
||||
"naive": {
|
||||
"layout_recognize": "DeepDOC",
|
||||
|
|
@ -365,16 +369,19 @@ def get_parser_config(chunk_method, parser_config):
|
|||
|
||||
default_config = key_mapping[chunk_method]
|
||||
|
||||
# If no parser_config provided, return default
|
||||
# If no parser_config provided, return default merged with base defaults
|
||||
if not parser_config:
|
||||
return default_config
|
||||
if default_config is None:
|
||||
return deep_merge(base_defaults, {})
|
||||
return deep_merge(base_defaults, default_config)
|
||||
|
||||
# If parser_config is provided, merge with defaults to ensure required fields exist
|
||||
if default_config is None:
|
||||
return parser_config
|
||||
return deep_merge(base_defaults, parser_config)
|
||||
|
||||
# Ensure raptor and graphrag fields have default values if not provided
|
||||
merged_config = deep_merge(default_config, parser_config)
|
||||
merged_config = deep_merge(base_defaults, default_config)
|
||||
merged_config = deep_merge(merged_config, parser_config)
|
||||
|
||||
return merged_config
|
||||
|
||||
|
|
|
|||
|
|
@ -49,6 +49,7 @@ class RetCode(IntEnum, CustomEnum):
|
|||
RUNNING = 106
|
||||
PERMISSION_ERROR = 108
|
||||
AUTHENTICATION_ERROR = 109
|
||||
BAD_REQUEST = 400
|
||||
UNAUTHORIZED = 401
|
||||
SERVER_ERROR = 500
|
||||
FORBIDDEN = 403
|
||||
|
|
|
|||
|
|
@ -217,6 +217,7 @@ OAUTH_GOOGLE_DRIVE_CLIENT_SECRET = os.environ.get(
|
|||
"OAUTH_GOOGLE_DRIVE_CLIENT_SECRET", ""
|
||||
)
|
||||
GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI = os.environ.get("GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/google-drive/oauth/web/callback")
|
||||
GMAIL_WEB_OAUTH_REDIRECT_URI = os.environ.get("GMAIL_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/gmail/oauth/web/callback")
|
||||
|
||||
CONFLUENCE_OAUTH_TOKEN_URL = "https://auth.atlassian.com/oauth/token"
|
||||
RATE_LIMIT_MESSAGE_LOWERCASE = "Rate limit exceeded".lower()
|
||||
|
|
|
|||
|
|
@ -1562,6 +1562,7 @@ class ConfluenceConnector(
|
|||
size_bytes=len(page_content.encode("utf-8")), # Calculate size in bytes
|
||||
doc_updated_at=datetime_from_string(page["version"]["when"]),
|
||||
primary_owners=primary_owners if primary_owners else None,
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
except Exception as e:
|
||||
logging.error(f"Error converting page {page.get('id', 'unknown')}: {e}")
|
||||
|
|
|
|||
|
|
@ -65,6 +65,7 @@ def _convert_message_to_document(
|
|||
blob=message.content.encode("utf-8"),
|
||||
extension=".txt",
|
||||
size_bytes=len(message.content.encode("utf-8")),
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
import logging
|
||||
import os
|
||||
from typing import Any
|
||||
|
||||
from google.oauth2.credentials import Credentials as OAuthCredentials
|
||||
from google.oauth2.service_account import Credentials as ServiceAccountCredentials
|
||||
from googleapiclient.errors import HttpError
|
||||
|
|
@ -9,10 +9,10 @@ from common.data_source.config import INDEX_BATCH_SIZE, SLIM_BATCH_SIZE, Documen
|
|||
from common.data_source.google_util.auth import get_google_creds
|
||||
from common.data_source.google_util.constant import DB_CREDENTIALS_PRIMARY_ADMIN_KEY, MISSING_SCOPES_ERROR_STR, SCOPE_INSTRUCTIONS, USER_FIELDS
|
||||
from common.data_source.google_util.resource import get_admin_service, get_gmail_service
|
||||
from common.data_source.google_util.util import _execute_single_retrieval, execute_paginated_retrieval
|
||||
from common.data_source.google_util.util import _execute_single_retrieval, execute_paginated_retrieval, sanitize_filename, clean_string
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector, SecondsSinceUnixEpoch, SlimConnectorWithPermSync
|
||||
from common.data_source.models import BasicExpertInfo, Document, ExternalAccess, GenerateDocumentsOutput, GenerateSlimDocumentOutput, SlimDocument, TextSection
|
||||
from common.data_source.utils import build_time_range_query, clean_email_and_extract_name, get_message_body, is_mail_service_disabled_error, time_str_to_utc
|
||||
from common.data_source.utils import build_time_range_query, clean_email_and_extract_name, get_message_body, is_mail_service_disabled_error, gmail_time_str_to_utc
|
||||
|
||||
# Constants for Gmail API fields
|
||||
THREAD_LIST_FIELDS = "nextPageToken, threads(id)"
|
||||
|
|
@ -67,7 +67,6 @@ def message_to_section(message: dict[str, Any]) -> tuple[TextSection, dict[str,
|
|||
message_data += f"{name}: {value}\n"
|
||||
|
||||
message_body_text: str = get_message_body(payload)
|
||||
|
||||
return TextSection(link=link, text=message_body_text + message_data), metadata
|
||||
|
||||
|
||||
|
|
@ -97,13 +96,15 @@ def thread_to_document(full_thread: dict[str, Any], email_used_to_fetch_thread:
|
|||
|
||||
if not semantic_identifier:
|
||||
semantic_identifier = message_metadata.get("subject", "")
|
||||
semantic_identifier = clean_string(semantic_identifier)
|
||||
semantic_identifier = sanitize_filename(semantic_identifier)
|
||||
|
||||
if message_metadata.get("updated_at"):
|
||||
updated_at = message_metadata.get("updated_at")
|
||||
|
||||
|
||||
updated_at_datetime = None
|
||||
if updated_at:
|
||||
updated_at_datetime = time_str_to_utc(updated_at)
|
||||
updated_at_datetime = gmail_time_str_to_utc(updated_at)
|
||||
|
||||
thread_id = full_thread.get("id")
|
||||
if not thread_id:
|
||||
|
|
@ -115,15 +116,24 @@ def thread_to_document(full_thread: dict[str, Any], email_used_to_fetch_thread:
|
|||
if not semantic_identifier:
|
||||
semantic_identifier = "(no subject)"
|
||||
|
||||
combined_sections = "\n\n".join(
|
||||
sec.text for sec in sections if hasattr(sec, "text")
|
||||
)
|
||||
blob = combined_sections
|
||||
size_bytes = len(blob)
|
||||
extension = '.txt'
|
||||
|
||||
return Document(
|
||||
id=thread_id,
|
||||
semantic_identifier=semantic_identifier,
|
||||
sections=sections,
|
||||
blob=blob,
|
||||
size_bytes=size_bytes,
|
||||
extension=extension,
|
||||
source=DocumentSource.GMAIL,
|
||||
primary_owners=primary_owners,
|
||||
secondary_owners=secondary_owners,
|
||||
doc_updated_at=updated_at_datetime,
|
||||
metadata={},
|
||||
metadata=message_metadata,
|
||||
external_access=ExternalAccess(
|
||||
external_user_emails={email_used_to_fetch_thread},
|
||||
external_user_group_ids=set(),
|
||||
|
|
@ -214,15 +224,13 @@ class GmailConnector(LoadConnector, PollConnector, SlimConnectorWithPermSync):
|
|||
q=query,
|
||||
continue_on_404_or_403=True,
|
||||
):
|
||||
full_threads = _execute_single_retrieval(
|
||||
full_thread = _execute_single_retrieval(
|
||||
retrieval_function=gmail_service.users().threads().get,
|
||||
list_key=None,
|
||||
userId=user_email,
|
||||
fields=THREAD_FIELDS,
|
||||
id=thread["id"],
|
||||
continue_on_404_or_403=True,
|
||||
)
|
||||
full_thread = list(full_threads)[0]
|
||||
doc = thread_to_document(full_thread, user_email)
|
||||
if doc is None:
|
||||
continue
|
||||
|
|
@ -310,4 +318,30 @@ class GmailConnector(LoadConnector, PollConnector, SlimConnectorWithPermSync):
|
|||
|
||||
|
||||
if __name__ == "__main__":
|
||||
pass
|
||||
import time
|
||||
import os
|
||||
from common.data_source.google_util.util import get_credentials_from_env
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
try:
|
||||
email = os.environ.get("GMAIL_TEST_EMAIL", "newyorkupperbay@gmail.com")
|
||||
creds = get_credentials_from_env(email, oauth=True, source="gmail")
|
||||
print("Credentials loaded successfully")
|
||||
print(f"{creds=}")
|
||||
|
||||
connector = GmailConnector(batch_size=2)
|
||||
print("GmailConnector initialized")
|
||||
connector.load_credentials(creds)
|
||||
print("Credentials loaded into connector")
|
||||
|
||||
print("Gmail is ready to use")
|
||||
|
||||
for file in connector._fetch_threads(
|
||||
int(time.time()) - 1 * 24 * 60 * 60,
|
||||
int(time.time()),
|
||||
):
|
||||
print("new batch","-"*80)
|
||||
for f in file:
|
||||
print(f)
|
||||
print("\n\n")
|
||||
except Exception as e:
|
||||
logging.exception(f"Error loading credentials: {e}")
|
||||
|
|
@ -1,7 +1,6 @@
|
|||
"""Google Drive connector"""
|
||||
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
|
@ -32,7 +31,6 @@ from common.data_source.google_drive.file_retrieval import (
|
|||
from common.data_source.google_drive.model import DriveRetrievalStage, GoogleDriveCheckpoint, GoogleDriveFileType, RetrievedDriveFile, StageCompletion
|
||||
from common.data_source.google_util.auth import get_google_creds
|
||||
from common.data_source.google_util.constant import DB_CREDENTIALS_PRIMARY_ADMIN_KEY, MISSING_SCOPES_ERROR_STR, USER_FIELDS
|
||||
from common.data_source.google_util.oauth_flow import ensure_oauth_token_dict
|
||||
from common.data_source.google_util.resource import GoogleDriveService, get_admin_service, get_drive_service
|
||||
from common.data_source.google_util.util import GoogleFields, execute_paginated_retrieval, get_file_owners
|
||||
from common.data_source.google_util.util_threadpool_concurrency import ThreadSafeDict
|
||||
|
|
@ -1138,39 +1136,6 @@ class GoogleDriveConnector(SlimConnectorWithPermSync, CheckpointedConnectorWithP
|
|||
return GoogleDriveCheckpoint.model_validate_json(checkpoint_json)
|
||||
|
||||
|
||||
def get_credentials_from_env(email: str, oauth: bool = False) -> dict:
|
||||
try:
|
||||
if oauth:
|
||||
raw_credential_string = os.environ["GOOGLE_DRIVE_OAUTH_CREDENTIALS_JSON_STR"]
|
||||
else:
|
||||
raw_credential_string = os.environ["GOOGLE_DRIVE_SERVICE_ACCOUNT_JSON_STR"]
|
||||
except KeyError:
|
||||
raise ValueError("Missing Google Drive credentials in environment variables")
|
||||
|
||||
try:
|
||||
credential_dict = json.loads(raw_credential_string)
|
||||
except json.JSONDecodeError:
|
||||
raise ValueError("Invalid JSON in Google Drive credentials")
|
||||
|
||||
if oauth:
|
||||
credential_dict = ensure_oauth_token_dict(credential_dict, DocumentSource.GOOGLE_DRIVE)
|
||||
|
||||
refried_credential_string = json.dumps(credential_dict)
|
||||
|
||||
DB_CREDENTIALS_DICT_TOKEN_KEY = "google_tokens"
|
||||
DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY = "google_service_account_key"
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY = "google_primary_admin"
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD = "authentication_method"
|
||||
|
||||
cred_key = DB_CREDENTIALS_DICT_TOKEN_KEY if oauth else DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY
|
||||
|
||||
return {
|
||||
cred_key: refried_credential_string,
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY: email,
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
||||
}
|
||||
|
||||
|
||||
class CheckpointOutputWrapper:
|
||||
"""
|
||||
Wraps a CheckpointOutput generator to give things back in a more digestible format.
|
||||
|
|
@ -1236,7 +1201,7 @@ def yield_all_docs_from_checkpoint_connector(
|
|||
|
||||
if __name__ == "__main__":
|
||||
import time
|
||||
|
||||
from common.data_source.google_util.util import get_credentials_from_env
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
|
||||
try:
|
||||
|
|
@ -1245,7 +1210,7 @@ if __name__ == "__main__":
|
|||
creds = get_credentials_from_env(email, oauth=True)
|
||||
print("Credentials loaded successfully")
|
||||
print(f"{creds=}")
|
||||
|
||||
sys.exit(0)
|
||||
connector = GoogleDriveConnector(
|
||||
include_shared_drives=False,
|
||||
shared_drive_urls=None,
|
||||
|
|
|
|||
|
|
@ -49,11 +49,11 @@ MISSING_SCOPES_ERROR_STR = "client not authorized for any of the scopes requeste
|
|||
SCOPE_INSTRUCTIONS = ""
|
||||
|
||||
|
||||
GOOGLE_DRIVE_WEB_OAUTH_POPUP_TEMPLATE = """<!DOCTYPE html>
|
||||
GOOGLE_WEB_OAUTH_POPUP_TEMPLATE = """<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8" />
|
||||
<title>Google Drive Authorization</title>
|
||||
<title>{title}</title>
|
||||
<style>
|
||||
body {{
|
||||
font-family: Arial, sans-serif;
|
||||
|
|
|
|||
|
|
@ -1,12 +1,17 @@
|
|||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import socket
|
||||
from collections.abc import Callable, Iterator
|
||||
from enum import Enum
|
||||
from typing import Any
|
||||
|
||||
import unicodedata
|
||||
from googleapiclient.errors import HttpError # type: ignore # type: ignore
|
||||
|
||||
from common.data_source.config import DocumentSource
|
||||
from common.data_source.google_drive.model import GoogleDriveFileType
|
||||
from common.data_source.google_util.oauth_flow import ensure_oauth_token_dict
|
||||
|
||||
|
||||
# See https://developers.google.com/drive/api/reference/rest/v3/files/list for more
|
||||
|
|
@ -117,6 +122,7 @@ def _execute_single_retrieval(
|
|||
"""Execute a single retrieval from Google Drive API"""
|
||||
try:
|
||||
results = retrieval_function(**request_kwargs).execute()
|
||||
|
||||
except HttpError as e:
|
||||
if e.resp.status >= 500:
|
||||
results = retrieval_function()
|
||||
|
|
@ -148,5 +154,110 @@ def _execute_single_retrieval(
|
|||
error,
|
||||
)
|
||||
results = retrieval_function()
|
||||
|
||||
return results
|
||||
|
||||
|
||||
def get_credentials_from_env(email: str, oauth: bool = False, source="drive") -> dict:
|
||||
try:
|
||||
if oauth:
|
||||
raw_credential_string = os.environ["GOOGLE_OAUTH_CREDENTIALS_JSON_STR"]
|
||||
else:
|
||||
raw_credential_string = os.environ["GOOGLE_SERVICE_ACCOUNT_JSON_STR"]
|
||||
except KeyError:
|
||||
raise ValueError("Missing Google Drive credentials in environment variables")
|
||||
|
||||
try:
|
||||
credential_dict = json.loads(raw_credential_string)
|
||||
except json.JSONDecodeError:
|
||||
raise ValueError("Invalid JSON in Google Drive credentials")
|
||||
|
||||
if oauth and source == "drive":
|
||||
credential_dict = ensure_oauth_token_dict(credential_dict, DocumentSource.GOOGLE_DRIVE)
|
||||
else:
|
||||
credential_dict = ensure_oauth_token_dict(credential_dict, DocumentSource.GMAIL)
|
||||
|
||||
refried_credential_string = json.dumps(credential_dict)
|
||||
|
||||
DB_CREDENTIALS_DICT_TOKEN_KEY = "google_tokens"
|
||||
DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY = "google_service_account_key"
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY = "google_primary_admin"
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD = "authentication_method"
|
||||
|
||||
cred_key = DB_CREDENTIALS_DICT_TOKEN_KEY if oauth else DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY
|
||||
|
||||
return {
|
||||
cred_key: refried_credential_string,
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY: email,
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
||||
}
|
||||
|
||||
def sanitize_filename(name: str) -> str:
|
||||
"""
|
||||
Soft sanitize for MinIO/S3:
|
||||
- Replace only prohibited characters with a space.
|
||||
- Preserve readability (no ugly underscores).
|
||||
- Collapse multiple spaces.
|
||||
"""
|
||||
if name is None:
|
||||
return "file.txt"
|
||||
|
||||
name = str(name).strip()
|
||||
|
||||
# Characters that MUST NOT appear in S3/MinIO object keys
|
||||
# Replace them with a space (not underscore)
|
||||
forbidden = r'[\\\?\#\%\*\:\|\<\>"]'
|
||||
name = re.sub(forbidden, " ", name)
|
||||
|
||||
# Replace slashes "/" (S3 interprets as folder) with space
|
||||
name = name.replace("/", " ")
|
||||
|
||||
# Collapse multiple spaces into one
|
||||
name = re.sub(r"\s+", " ", name)
|
||||
|
||||
# Trim both ends
|
||||
name = name.strip()
|
||||
|
||||
# Enforce reasonable max length
|
||||
if len(name) > 200:
|
||||
base, ext = os.path.splitext(name)
|
||||
name = base[:180].rstrip() + ext
|
||||
|
||||
# Ensure there is an extension (your original logic)
|
||||
if not os.path.splitext(name)[1]:
|
||||
name += ".txt"
|
||||
|
||||
return name
|
||||
|
||||
|
||||
def clean_string(text: str | None) -> str | None:
|
||||
"""
|
||||
Clean a string to make it safe for insertion into MySQL (utf8mb4).
|
||||
- Normalize Unicode
|
||||
- Remove control characters / zero-width characters
|
||||
- Optionally remove high-plane emoji and symbols
|
||||
"""
|
||||
if text is None:
|
||||
return None
|
||||
|
||||
# 0. Ensure the value is a string
|
||||
text = str(text)
|
||||
|
||||
# 1. Normalize Unicode (NFC)
|
||||
text = unicodedata.normalize("NFC", text)
|
||||
|
||||
# 2. Remove ASCII control characters (except tab, newline, carriage return)
|
||||
text = re.sub(r"[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]", "", text)
|
||||
|
||||
# 3. Remove zero-width characters / BOM
|
||||
text = re.sub(r"[\u200b-\u200d\uFEFF]", "", text)
|
||||
|
||||
# 4. Remove high Unicode characters (emoji, special symbols)
|
||||
text = re.sub(r"[\U00010000-\U0010FFFF]", "", text)
|
||||
|
||||
# 5. Final fallback: strip any invalid UTF-8 sequences
|
||||
try:
|
||||
text.encode("utf-8")
|
||||
except UnicodeEncodeError:
|
||||
text = text.encode("utf-8", errors="ignore").decode("utf-8")
|
||||
|
||||
return text
|
||||
|
|
@ -30,7 +30,6 @@ class LoadConnector(ABC):
|
|||
"""Load documents from state"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def validate_connector_settings(self) -> None:
|
||||
"""Validate connector settings"""
|
||||
pass
|
||||
|
|
|
|||
|
|
@ -94,6 +94,7 @@ class Document(BaseModel):
|
|||
blob: bytes
|
||||
doc_updated_at: datetime
|
||||
size_bytes: int
|
||||
metadata: Optional[dict[str, Any]] = None
|
||||
|
||||
|
||||
class BasicExpertInfo(BaseModel):
|
||||
|
|
|
|||
|
|
@ -733,7 +733,7 @@ def build_time_range_query(
|
|||
"""Build time range query for Gmail API"""
|
||||
query = ""
|
||||
if time_range_start is not None and time_range_start != 0:
|
||||
query += f"after:{int(time_range_start)}"
|
||||
query += f"after:{int(time_range_start) + 1}"
|
||||
if time_range_end is not None and time_range_end != 0:
|
||||
query += f" before:{int(time_range_end)}"
|
||||
query = query.strip()
|
||||
|
|
@ -778,6 +778,15 @@ def time_str_to_utc(time_str: str):
|
|||
return datetime.fromisoformat(time_str.replace("Z", "+00:00"))
|
||||
|
||||
|
||||
def gmail_time_str_to_utc(time_str: str):
|
||||
"""Convert Gmail RFC 2822 time string to UTC."""
|
||||
from email.utils import parsedate_to_datetime
|
||||
from datetime import timezone
|
||||
|
||||
dt = parsedate_to_datetime(time_str)
|
||||
return dt.astimezone(timezone.utc)
|
||||
|
||||
|
||||
# Notion Utilities
|
||||
T = TypeVar("T")
|
||||
|
||||
|
|
|
|||
|
|
@ -7,6 +7,20 @@
|
|||
"status": "1",
|
||||
"rank": "999",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "gpt-5.1",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5.1-chat-latest",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
|
|
@ -269,20 +283,6 @@
|
|||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.5",
|
||||
"tags": "LLM,CHAT,131K",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3.1",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "hunyuan-a13b-instruct",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
|
|
@ -324,6 +324,34 @@
|
|||
"max_tokens": 262000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-ocr",
|
||||
"tags": "LLM,8k",
|
||||
"max_tokens": 8000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-235b-a22b-instruct-2507",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
"max_tokens": 256000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.6",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "minimax-m2",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
}
|
||||
]
|
||||
},
|
||||
|
|
@ -3218,6 +3246,13 @@
|
|||
"status": "1",
|
||||
"rank": "990",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "claude-opus-4-5-20251101",
|
||||
"tags": "LLM,CHAT,IMAGE2TEXT,200k",
|
||||
"max_tokens": 204800,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-opus-4-1-20250805",
|
||||
"tags": "LLM,CHAT,IMAGE2TEXT,200k",
|
||||
|
|
|
|||
|
|
@ -138,7 +138,6 @@ class RAGFlowHtmlParser:
|
|||
"metadata": {"table_id": table_id, "index": table_list.index(t)}})
|
||||
return table_info_list
|
||||
else:
|
||||
block_id = None
|
||||
if str.lower(element.name) in BLOCK_TAGS:
|
||||
block_id = str(uuid.uuid1())
|
||||
for child in element.children:
|
||||
|
|
@ -172,7 +171,7 @@ class RAGFlowHtmlParser:
|
|||
if tag_name == "table":
|
||||
table_info_list.append(item)
|
||||
else:
|
||||
current_content += (" " if current_content else "" + content)
|
||||
current_content += (" " if current_content else "") + content
|
||||
if current_content:
|
||||
block_content.append(current_content)
|
||||
return block_content, table_info_list
|
||||
|
|
|
|||
|
|
@ -402,7 +402,6 @@ class RAGFlowPdfParser:
|
|||
continue
|
||||
else:
|
||||
score = 0
|
||||
print(f"{k=},{score=}",flush=True)
|
||||
if score > best_score:
|
||||
best_score = score
|
||||
best_k = k
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@
|
|||
import logging
|
||||
import math
|
||||
import os
|
||||
import re
|
||||
# import re
|
||||
from collections import Counter
|
||||
from copy import deepcopy
|
||||
|
||||
|
|
@ -62,8 +62,9 @@ class LayoutRecognizer(Recognizer):
|
|||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
def __is_garbage(b):
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
return any([re.search(p, b["text"]) for p in patt])
|
||||
return False
|
||||
# patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
# return any([re.search(p, b["text"]) for p in patt])
|
||||
|
||||
if self.client:
|
||||
layouts = self.client.predict(image_list)
|
||||
|
|
|
|||
12
docs/faq.mdx
12
docs/faq.mdx
|
|
@ -323,9 +323,9 @@ The status of a Docker container status does not necessarily reflect the status
|
|||
|
||||
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
|
||||
3. If your container keeps restarting, ensure `vm.max_map_count` >= 262144 as per [this README](https://github.com/infiniflow/ragflow?tab=readme-ov-file#-start-up-the-server). Updating the `vm.max_map_count` value in **/etc/sysctl.conf** is required, if you wish to keep your change permanent. Note that this configuration works only for Linux.
|
||||
|
||||
|
|
@ -456,9 +456,9 @@ To switch your document engine from Elasticsearch to [Infinity](https://github.c
|
|||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
3. Restart your Docker image:
|
||||
|
|
|
|||
|
|
@ -22,7 +22,7 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
|||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
|
|
@ -91,7 +91,7 @@ Update your MCP server's name, URL (including the API key), server type, and oth
|
|||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
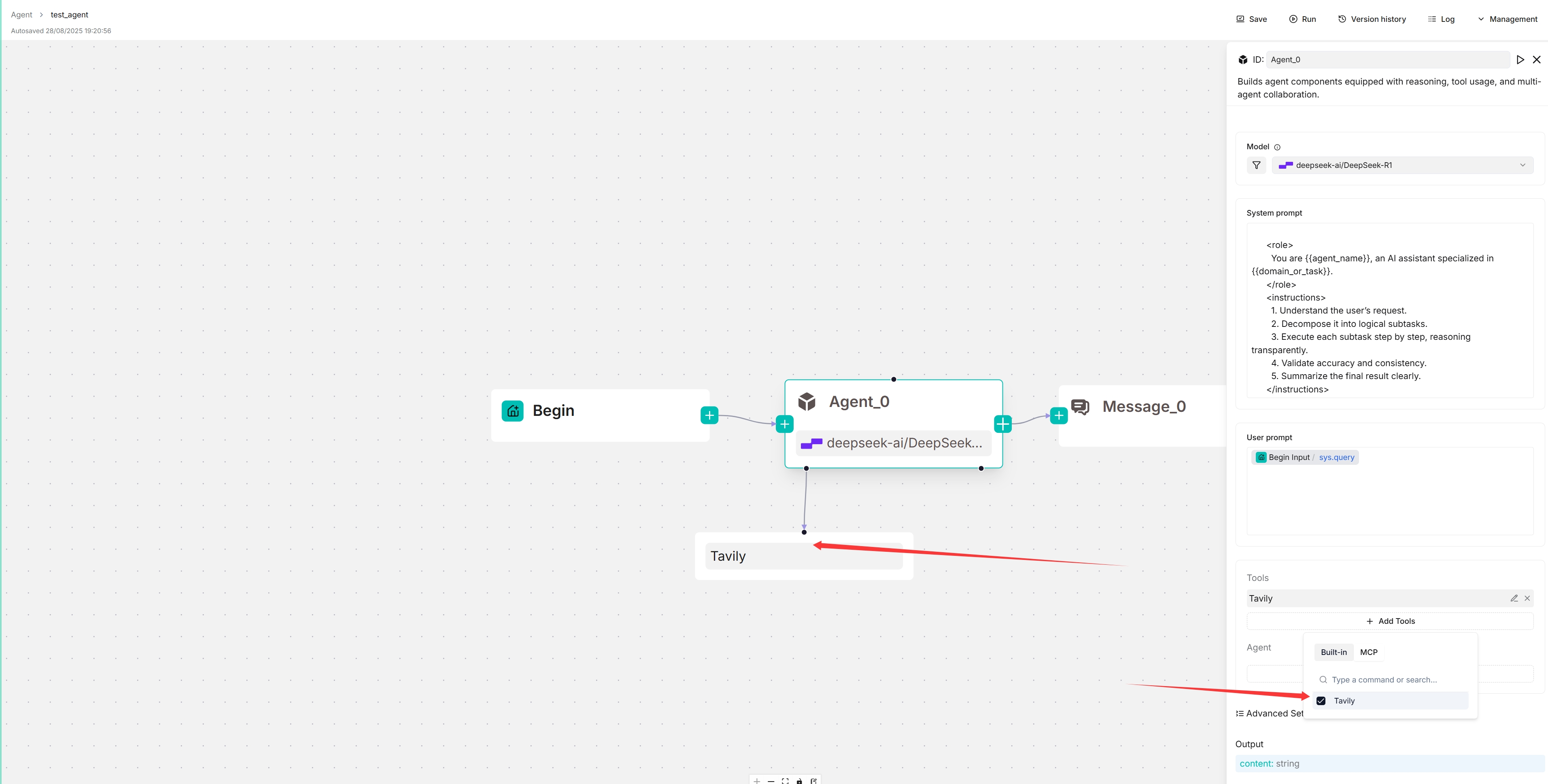
|
||||

|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
|
|
|
|||
|
|
@ -62,9 +62,9 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
|||
|
||||
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Start the RAGFlow service as usual.
|
||||
|
||||
|
|
@ -74,24 +74,24 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
|||
|
||||
1. Initialize the environment variables:
|
||||
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
|
||||
2. Launch the sandbox services with Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
3. Test the sandbox setup:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
|
||||
### Using Makefile
|
||||
|
||||
|
|
|
|||
|
|
@ -83,13 +83,13 @@ You start an AI conversation by creating an assistant.
|
|||
|
||||
1. Click the light bulb icon above the answer to view the expanded system prompt:
|
||||
|
||||
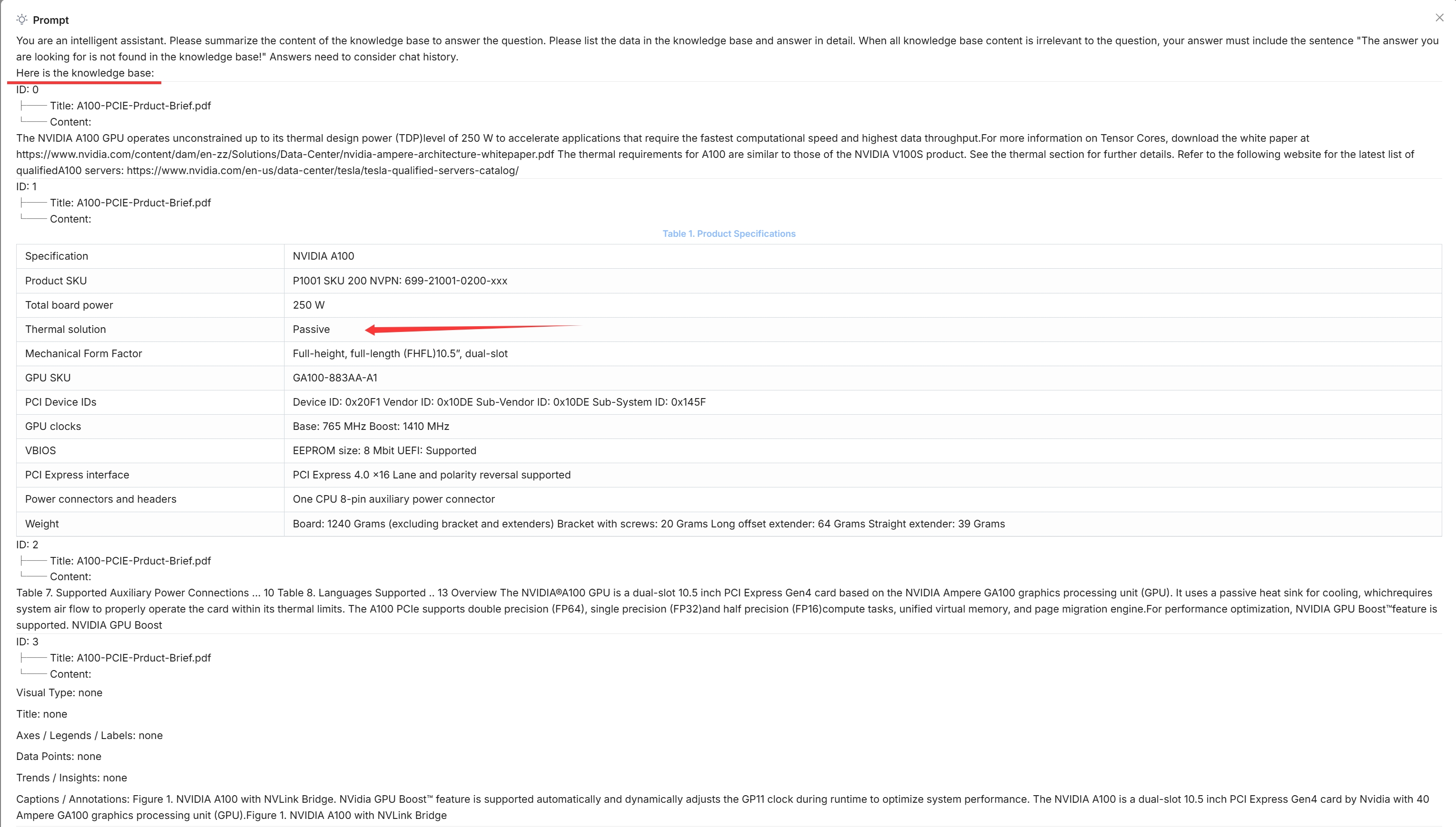
|
||||

|
||||
|
||||
*The light bulb icon is available only for the current dialogue.*
|
||||
|
||||
2. Scroll down the expanded prompt to view the time consumed for each task:
|
||||
|
||||

|
||||

|
||||
:::
|
||||
|
||||
## Update settings of an existing chat assistant
|
||||
|
|
|
|||
|
|
@ -56,9 +56,9 @@ Once a tag set is created, you can apply it to your dataset:
|
|||
1. Navigate to the **Configuration** page of your dataset.
|
||||
2. Select the tag set from the **Tag sets** dropdown and click **Save** to confirm.
|
||||
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
|
|
|||
|
|
@ -39,8 +39,10 @@ If you have not installed Docker on your local machine (Windows, Mac, or Linux),
|
|||
|
||||
This section provides instructions on setting up the RAGFlow server on Linux. If you are on a different operating system, no worries. Most steps are alike.
|
||||
|
||||
1. Ensure `vm.max_map_count` ≥ 262144.
|
||||
|
||||
<details>
|
||||
<summary>1. Ensure <code>vm.max_map_count</code> ≥ 262144:</summary>
|
||||
<summary>Expand to show details:</summary>
|
||||
|
||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||
|
||||
|
|
@ -194,22 +196,22 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
|||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
|
||||
4. Check the server status after having the server up and running:
|
||||
|
||||
|
|
@ -229,15 +231,15 @@ The image size shown refers to the size of the *downloaded* Docker image, which
|
|||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
|
||||
## Configure LLMs
|
||||
|
||||
|
|
@ -278,9 +280,9 @@ To create your first dataset:
|
|||
|
||||
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
|
||||
_You are taken to the **Dataset** page of your dataset._
|
||||
|
||||
|
|
@ -290,10 +292,10 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
|||
|
||||
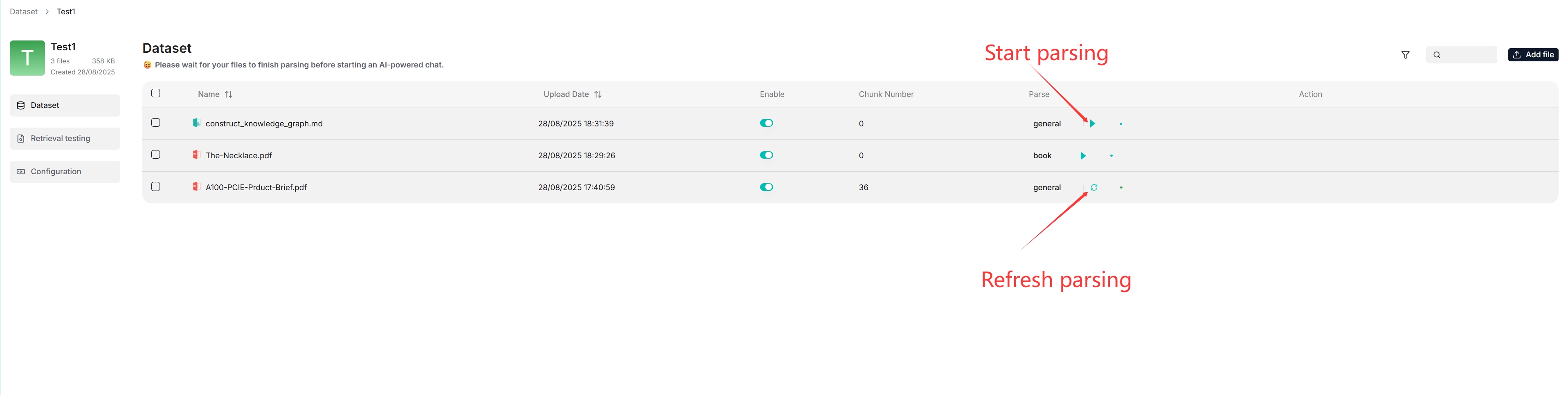
|
||||
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
## Intervene with file parsing
|
||||
|
||||
|
|
@ -311,9 +313,9 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
|||
|
||||
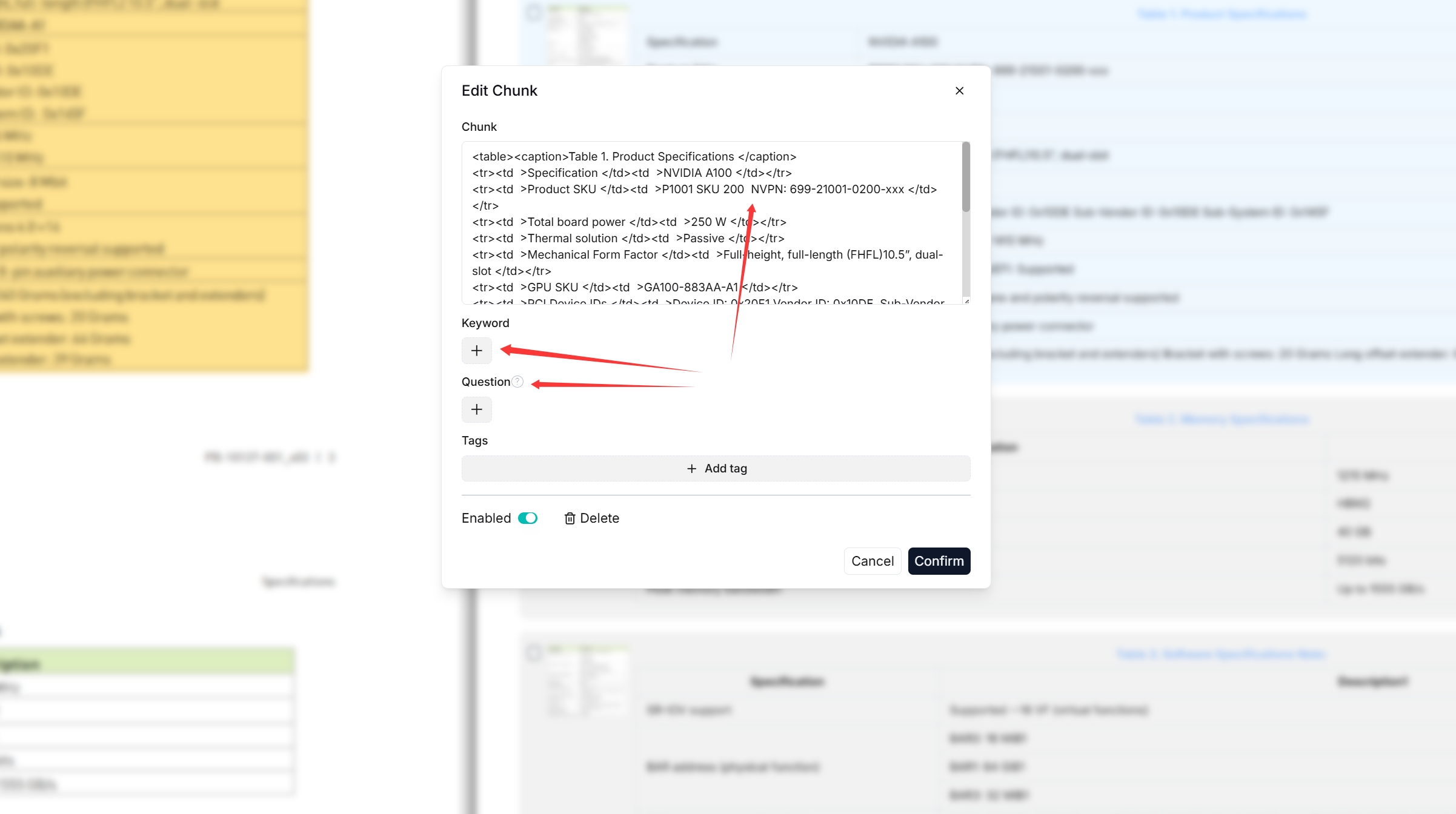
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double check if your configurations work:
|
||||
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ from rag.app import naive
|
|||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from rag.nlp import bullets_category, is_english,remove_contents_table, \
|
||||
hierarchical_merge, make_colon_as_title, naive_merge, random_choices, tokenize_table, \
|
||||
tokenize_chunks
|
||||
tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer
|
||||
from deepdoc.parser import PdfParser, HtmlParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_docx_wrapper
|
||||
|
|
@ -175,6 +175,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
|
||||
return res
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ import re
|
|||
|
||||
from common.constants import ParserType
|
||||
from io import BytesIO
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level, attach_media_context
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from deepdoc.parser import PdfParser, DocxParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper,vision_figure_parser_docx_wrapper
|
||||
|
|
@ -155,7 +155,7 @@ class Docx(DocxParser):
|
|||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
ti_list.append((f'{sum_question}\n{last_answer}', last_image))
|
||||
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
|
|
@ -231,14 +231,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
if isinstance(poss, str):
|
||||
poss = pdf_parser.extract_positions(poss)
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
pn = first[0]
|
||||
pn = first[0]
|
||||
|
||||
if isinstance(pn, list):
|
||||
pn = pn[0] # [pn] -> pn
|
||||
poss[0] = (pn, *first[1:])
|
||||
|
||||
return (txt, layoutno, poss)
|
||||
|
||||
|
||||
|
||||
sections = [_normalize_section(sec) for sec in sections]
|
||||
|
||||
|
|
@ -247,7 +247,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
if len(sections) > 0 and len(pdf_parser.outlines) / len(sections) > 0.03:
|
||||
|
|
@ -310,6 +310,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.docx?$", filename, re.IGNORECASE):
|
||||
|
|
@ -325,10 +329,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
d["doc_type_kwd"] = "image"
|
||||
tokenize(d, text, eng)
|
||||
res.append(d)
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
else:
|
||||
raise NotImplementedError("file type not supported yet(pdf and docx supported)")
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ from deepdoc.parser.pdf_parser import PlainParser, VisionParser
|
|||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.docling_parser import DoclingParser
|
||||
from deepdoc.parser.tcadp_parser import TCADPParser
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None ,**kwargs):
|
||||
callback = callback
|
||||
|
|
@ -616,6 +616,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
parser_config = kwargs.get(
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC", "analyze_hyperlink": True})
|
||||
table_context_size = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_context_size = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
final_sections = False
|
||||
doc = {
|
||||
"docnm_kwd": filename,
|
||||
|
|
@ -686,6 +688,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
logging.info("naive_merge({}): {}".format(filename, timer() - st))
|
||||
res.extend(embed_res)
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
|
|
@ -947,6 +951,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
res.extend(embed_res)
|
||||
if url_res:
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ import re
|
|||
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper
|
||||
from common.constants import ParserType
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks, attach_media_context
|
||||
from deepdoc.parser import PdfParser
|
||||
import numpy as np
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
|
|
@ -150,7 +150,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC"})
|
||||
if re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
layout_recognizer = parser_config.get("layout_recognize", "DeepDOC")
|
||||
|
||||
|
||||
if isinstance(layout_recognizer, bool):
|
||||
layout_recognizer = "DeepDOC" if layout_recognizer else "Plain Text"
|
||||
|
||||
|
|
@ -234,6 +234,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||
chunks.append(txt)
|
||||
last_sid = sec_id
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -20,11 +20,11 @@ import re
|
|||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import rag_tokenizer, tokenize
|
||||
from common.constants import LLMType
|
||||
from common.string_utils import clean_markdown_block
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import attach_media_context, rag_tokenizer, tokenize
|
||||
|
||||
ocr = OCR()
|
||||
|
||||
|
|
@ -39,9 +39,16 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
|||
}
|
||||
eng = lang.lower() == "english"
|
||||
|
||||
parser_config = kwargs.get("parser_config", {}) or {}
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
|
||||
if any(filename.lower().endswith(ext) for ext in VIDEO_EXTS):
|
||||
try:
|
||||
doc.update({"doc_type_kwd": "video"})
|
||||
doc.update(
|
||||
{
|
||||
"doc_type_kwd": "video",
|
||||
}
|
||||
)
|
||||
cv_mdl = LLMBundle(tenant_id, llm_type=LLMType.IMAGE2TEXT, lang=lang)
|
||||
ans = cv_mdl.chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename)
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
|
|
@ -64,7 +71,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
|||
if (eng and len(txt.split()) > 32) or len(txt) > 32:
|
||||
tokenize(doc, txt, eng)
|
||||
callback(0.8, "OCR results is too long to use CV LLM.")
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
|
||||
try:
|
||||
callback(0.4, "Use CV LLM to describe the picture.")
|
||||
|
|
@ -76,7 +83,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
|||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
txt += "\n" + ans
|
||||
tokenize(doc, txt, eng)
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
except Exception as e:
|
||||
callback(prog=-1, msg=str(e))
|
||||
|
||||
|
|
@ -103,7 +110,7 @@ def vision_llm_chunk(binary, vision_model, prompt=None, callback=None):
|
|||
img_binary.seek(0)
|
||||
img_binary.truncate()
|
||||
img.save(img_binary, format="PNG")
|
||||
|
||||
|
||||
img_binary.seek(0)
|
||||
ans = clean_markdown_block(vision_model.describe_with_prompt(img_binary.read(), prompt))
|
||||
txt += "\n" + ans
|
||||
|
|
|
|||
|
|
@ -19,16 +19,16 @@ import random
|
|||
import re
|
||||
from functools import partial
|
||||
|
||||
import trio
|
||||
import numpy as np
|
||||
import trio
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from common import settings
|
||||
from common.constants import LLMType
|
||||
from common.misc_utils import get_uuid
|
||||
from rag.utils.base64_image import image2id
|
||||
from deepdoc.parser import ExcelParser
|
||||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.pdf_parser import PlainParser, RAGFlowPdfParser, VisionParser
|
||||
|
|
@ -37,7 +37,8 @@ from rag.app.naive import Docx
|
|||
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||
from rag.flow.parser.schema import ParserFromUpstream
|
||||
from rag.llm.cv_model import Base as VLM
|
||||
from common import settings
|
||||
from rag.nlp import attach_media_context
|
||||
from rag.utils.base64_image import image2id
|
||||
|
||||
|
||||
class ParserParam(ProcessParamBase):
|
||||
|
|
@ -61,15 +62,18 @@ class ParserParam(ProcessParamBase):
|
|||
"json",
|
||||
],
|
||||
"image": [
|
||||
"text"
|
||||
"text",
|
||||
],
|
||||
"email": [
|
||||
"text",
|
||||
"json",
|
||||
],
|
||||
"email": ["text", "json"],
|
||||
"text&markdown": [
|
||||
"text",
|
||||
"json"
|
||||
"json",
|
||||
],
|
||||
"audio": [
|
||||
"json"
|
||||
"json",
|
||||
],
|
||||
"video": [],
|
||||
}
|
||||
|
|
@ -82,6 +86,8 @@ class ParserParam(ProcessParamBase):
|
|||
"pdf",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"spreadsheet": {
|
||||
"parse_method": "deepdoc", # deepdoc/tcadp_parser
|
||||
|
|
@ -91,6 +97,8 @@ class ParserParam(ProcessParamBase):
|
|||
"xlsx",
|
||||
"csv",
|
||||
],
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"word": {
|
||||
"suffix": [
|
||||
|
|
@ -98,18 +106,24 @@ class ParserParam(ProcessParamBase):
|
|||
"docx",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"text&markdown": {
|
||||
"suffix": ["md", "markdown", "mdx", "txt"],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"slides": {
|
||||
"parse_method": "deepdoc", # deepdoc/tcadp_parser
|
||||
"suffix": [
|
||||
"pptx",
|
||||
"ppt"
|
||||
"ppt",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"image": {
|
||||
"parse_method": "ocr",
|
||||
|
|
@ -121,13 +135,14 @@ class ParserParam(ProcessParamBase):
|
|||
},
|
||||
"email": {
|
||||
"suffix": [
|
||||
"eml", "msg"
|
||||
"eml",
|
||||
"msg",
|
||||
],
|
||||
"fields": ["from", "to", "cc", "bcc", "date", "subject", "body", "attachments", "metadata"],
|
||||
"output_format": "json",
|
||||
},
|
||||
"audio": {
|
||||
"suffix":[
|
||||
"suffix": [
|
||||
"da",
|
||||
"wave",
|
||||
"wav",
|
||||
|
|
@ -142,15 +157,15 @@ class ParserParam(ProcessParamBase):
|
|||
"realaudio",
|
||||
"vqf",
|
||||
"oggvorbis",
|
||||
"ape"
|
||||
"ape",
|
||||
],
|
||||
"output_format": "text",
|
||||
},
|
||||
"video": {
|
||||
"suffix":[
|
||||
"suffix": [
|
||||
"mp4",
|
||||
"avi",
|
||||
"mkv"
|
||||
"mkv",
|
||||
],
|
||||
"output_format": "text",
|
||||
},
|
||||
|
|
@ -253,7 +268,7 @@ class Parser(ProcessBase):
|
|||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
sections, _ = tcadp_parser.parse_pdf(
|
||||
filepath=name,
|
||||
|
|
@ -261,7 +276,7 @@ class Parser(ProcessBase):
|
|||
callback=self.callback,
|
||||
file_type="PDF",
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
bboxes = []
|
||||
for section, position_tag in sections:
|
||||
|
|
@ -269,17 +284,20 @@ class Parser(ProcessBase):
|
|||
# Extract position information from TCADP's position tag
|
||||
# Format: @@{page_number}\t{x0}\t{x1}\t{top}\t{bottom}##
|
||||
import re
|
||||
|
||||
match = re.match(r"@@([0-9-]+)\t([0-9.]+)\t([0-9.]+)\t([0-9.]+)\t([0-9.]+)##", position_tag)
|
||||
if match:
|
||||
pn, x0, x1, top, bott = match.groups()
|
||||
bboxes.append({
|
||||
"page_number": int(pn.split('-')[0]), # Take the first page number
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": section
|
||||
})
|
||||
bboxes.append(
|
||||
{
|
||||
"page_number": int(pn.split("-")[0]), # Take the first page number
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": section,
|
||||
}
|
||||
)
|
||||
else:
|
||||
# If no position info, add as text without position
|
||||
bboxes.append({"text": section})
|
||||
|
|
@ -291,7 +309,30 @@ class Parser(ProcessBase):
|
|||
bboxes = []
|
||||
for t, poss in lines:
|
||||
for pn, x0, x1, top, bott in RAGFlowPdfParser.extract_positions(poss):
|
||||
bboxes.append({"page_number": int(pn[0]), "x0": float(x0), "x1": float(x1), "top": float(top), "bottom": float(bott), "text": t})
|
||||
bboxes.append(
|
||||
{
|
||||
"page_number": int(pn[0]),
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": t,
|
||||
}
|
||||
)
|
||||
|
||||
for b in bboxes:
|
||||
text_val = b.get("text", "")
|
||||
has_text = isinstance(text_val, str) and text_val.strip()
|
||||
layout = b.get("layout_type")
|
||||
if layout == "figure" or (b.get("image") and not has_text):
|
||||
b["doc_type_kwd"] = "image"
|
||||
elif layout == "table":
|
||||
b["doc_type_kwd"] = "table"
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
bboxes = attach_media_context(bboxes, table_ctx, image_ctx)
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
self.set_output("json", bboxes)
|
||||
|
|
@ -319,7 +360,7 @@ class Parser(ProcessBase):
|
|||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
raise RuntimeError("TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
|
|
@ -337,7 +378,7 @@ class Parser(ProcessBase):
|
|||
callback=self.callback,
|
||||
file_type=file_type,
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
|
||||
# Process TCADP parser output based on configured output_format
|
||||
|
|
@ -365,7 +406,12 @@ class Parser(ProcessBase):
|
|||
# Add tables as text
|
||||
for table in tables:
|
||||
if table:
|
||||
result.append({"text": table})
|
||||
result.append({"text": table, "doc_type_kwd": "table"})
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
result = attach_media_context(result, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", result)
|
||||
|
||||
|
|
@ -400,7 +446,13 @@ class Parser(ProcessBase):
|
|||
if conf.get("output_format") == "json":
|
||||
sections, tbls = docx_parser(name, binary=blob)
|
||||
sections = [{"text": section[0], "image": section[1]} for section in sections if section]
|
||||
sections.extend([{"text": tb, "image": None} for ((_,tb), _) in tbls])
|
||||
sections.extend([{"text": tb, "image": None, "doc_type_kwd": "table"} for ((_, tb), _) in tbls])
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
sections = attach_media_context(sections, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", sections)
|
||||
elif conf.get("output_format") == "markdown":
|
||||
markdown_text = docx_parser.to_markdown(name, binary=blob)
|
||||
|
|
@ -420,7 +472,7 @@ class Parser(ProcessBase):
|
|||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
raise RuntimeError("TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
|
|
@ -439,7 +491,7 @@ class Parser(ProcessBase):
|
|||
callback=self.callback,
|
||||
file_type=file_type,
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
|
||||
# Process TCADP parser output - PPT only supports json format
|
||||
|
|
@ -454,7 +506,12 @@ class Parser(ProcessBase):
|
|||
# Add tables as text
|
||||
for table in tables:
|
||||
if table:
|
||||
result.append({"text": table})
|
||||
result.append({"text": table, "doc_type_kwd": "table"})
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
result = attach_media_context(result, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", result)
|
||||
else:
|
||||
|
|
@ -469,6 +526,10 @@ class Parser(ProcessBase):
|
|||
# json
|
||||
assert conf.get("output_format") == "json", "have to be json for ppt"
|
||||
if conf.get("output_format") == "json":
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
sections = attach_media_context(sections, table_ctx, image_ctx)
|
||||
self.set_output("json", sections)
|
||||
|
||||
def _markdown(self, name, blob):
|
||||
|
|
@ -508,11 +569,15 @@ class Parser(ProcessBase):
|
|||
|
||||
json_results.append(json_result)
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
json_results = attach_media_context(json_results, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", json_results)
|
||||
else:
|
||||
self.set_output("text", "\n".join([section_text for section_text, _ in sections]))
|
||||
|
||||
|
||||
def _image(self, name, blob):
|
||||
from deepdoc.vision import OCR
|
||||
|
||||
|
|
@ -588,7 +653,7 @@ class Parser(ProcessBase):
|
|||
from email.parser import BytesParser
|
||||
|
||||
msg = BytesParser(policy=policy.default).parse(io.BytesIO(blob))
|
||||
email_content['metadata'] = {}
|
||||
email_content["metadata"] = {}
|
||||
# handle header info
|
||||
for header, value in msg.items():
|
||||
# get fields like from, to, cc, bcc, date, subject
|
||||
|
|
@ -600,6 +665,7 @@ class Parser(ProcessBase):
|
|||
# get body
|
||||
if "body" in target_fields:
|
||||
body_text, body_html = [], []
|
||||
|
||||
def _add_content(m, content_type):
|
||||
def _decode_payload(payload, charset, target_list):
|
||||
try:
|
||||
|
|
@ -641,14 +707,17 @@ class Parser(ProcessBase):
|
|||
if dispositions[0].lower() == "attachment":
|
||||
filename = part.get_filename()
|
||||
payload = part.get_payload(decode=True).decode(part.get_content_charset())
|
||||
attachments.append({
|
||||
"filename": filename,
|
||||
"payload": payload,
|
||||
})
|
||||
attachments.append(
|
||||
{
|
||||
"filename": filename,
|
||||
"payload": payload,
|
||||
}
|
||||
)
|
||||
email_content["attachments"] = attachments
|
||||
else:
|
||||
# handle msg file
|
||||
import extract_msg
|
||||
|
||||
print("handle a msg file.")
|
||||
msg = extract_msg.Message(blob)
|
||||
# handle header info
|
||||
|
|
@ -662,9 +731,9 @@ class Parser(ProcessBase):
|
|||
}
|
||||
email_content.update({k: v for k, v in basic_content.items() if k in target_fields})
|
||||
# get metadata
|
||||
email_content['metadata'] = {
|
||||
'message_id': msg.messageId,
|
||||
'in_reply_to': msg.inReplyTo,
|
||||
email_content["metadata"] = {
|
||||
"message_id": msg.messageId,
|
||||
"in_reply_to": msg.inReplyTo,
|
||||
}
|
||||
# get body
|
||||
if "body" in target_fields:
|
||||
|
|
@ -675,29 +744,31 @@ class Parser(ProcessBase):
|
|||
if "attachments" in target_fields:
|
||||
attachments = []
|
||||
for t in msg.attachments:
|
||||
attachments.append({
|
||||
"filename": t.name,
|
||||
"payload": t.data.decode("utf-8")
|
||||
})
|
||||
attachments.append(
|
||||
{
|
||||
"filename": t.name,
|
||||
"payload": t.data.decode("utf-8"),
|
||||
}
|
||||
)
|
||||
email_content["attachments"] = attachments
|
||||
|
||||
if conf["output_format"] == "json":
|
||||
self.set_output("json", [email_content])
|
||||
else:
|
||||
content_txt = ''
|
||||
content_txt = ""
|
||||
for k, v in email_content.items():
|
||||
if isinstance(v, str):
|
||||
# basic info
|
||||
content_txt += f'{k}:{v}' + "\n"
|
||||
content_txt += f"{k}:{v}" + "\n"
|
||||
elif isinstance(v, dict):
|
||||
# metadata
|
||||
content_txt += f'{k}:{json.dumps(v)}' + "\n"
|
||||
content_txt += f"{k}:{json.dumps(v)}" + "\n"
|
||||
elif isinstance(v, list):
|
||||
# attachments or others
|
||||
for fb in v:
|
||||
if isinstance(fb, dict):
|
||||
# attachments
|
||||
content_txt += f'{fb["filename"]}:{fb["payload"]}' + "\n"
|
||||
content_txt += f"{fb['filename']}:{fb['payload']}" + "\n"
|
||||
else:
|
||||
# str, usually plain text
|
||||
content_txt += fb
|
||||
|
|
|
|||
|
|
@ -132,6 +132,11 @@ class Base(ABC):
|
|||
|
||||
gen_conf = {k: v for k, v in gen_conf.items() if k in allowed_conf}
|
||||
|
||||
model_name_lower = (self.model_name or "").lower()
|
||||
# gpt-5 and gpt-5.1 endpoints have inconsistent parameter support, clear custom generation params to prevent unexpected issues
|
||||
if "gpt-5" in model_name_lower:
|
||||
gen_conf = {}
|
||||
|
||||
return gen_conf
|
||||
|
||||
def _chat(self, history, gen_conf, **kwargs):
|
||||
|
|
|
|||
|
|
@ -318,6 +318,7 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
|||
d = copy.deepcopy(doc)
|
||||
tokenize(d, rows, eng)
|
||||
d["content_with_weight"] = rows
|
||||
d["doc_type_kwd"] = "table"
|
||||
if img:
|
||||
d["image"] = img
|
||||
d["doc_type_kwd"] = "image"
|
||||
|
|
@ -330,6 +331,7 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
|||
d = copy.deepcopy(doc)
|
||||
r = de.join(rows[i:i + batch_size])
|
||||
tokenize(d, r, eng)
|
||||
d["doc_type_kwd"] = "table"
|
||||
if img:
|
||||
d["image"] = img
|
||||
d["doc_type_kwd"] = "image"
|
||||
|
|
@ -338,6 +340,194 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
|||
return res
|
||||
|
||||
|
||||
def attach_media_context(chunks, table_context_size=0, image_context_size=0):
|
||||
"""
|
||||
Attach surrounding text chunk content to media chunks (table/image).
|
||||
Best-effort ordering: if positional info exists on any chunk, use it to
|
||||
order chunks before collecting context; otherwise keep original order.
|
||||
"""
|
||||
if not chunks or (table_context_size <= 0 and image_context_size <= 0):
|
||||
return chunks
|
||||
|
||||
def is_image_chunk(ck):
|
||||
if ck.get("doc_type_kwd") == "image":
|
||||
return True
|
||||
|
||||
text_val = ck.get("content_with_weight") if isinstance(ck.get("content_with_weight"), str) else ck.get("text")
|
||||
has_text = isinstance(text_val, str) and text_val.strip()
|
||||
return bool(ck.get("image")) and not has_text
|
||||
|
||||
def is_table_chunk(ck):
|
||||
return ck.get("doc_type_kwd") == "table"
|
||||
|
||||
def is_text_chunk(ck):
|
||||
return not is_image_chunk(ck) and not is_table_chunk(ck)
|
||||
|
||||
def get_text(ck):
|
||||
if isinstance(ck.get("content_with_weight"), str):
|
||||
return ck["content_with_weight"]
|
||||
if isinstance(ck.get("text"), str):
|
||||
return ck["text"]
|
||||
return ""
|
||||
|
||||
def split_sentences(text):
|
||||
pattern = r"([.。!?!?;;::\n])"
|
||||
parts = re.split(pattern, text)
|
||||
sentences = []
|
||||
buf = ""
|
||||
for p in parts:
|
||||
if not p:
|
||||
continue
|
||||
if re.fullmatch(pattern, p):
|
||||
buf += p
|
||||
sentences.append(buf)
|
||||
buf = ""
|
||||
else:
|
||||
buf += p
|
||||
if buf:
|
||||
sentences.append(buf)
|
||||
return sentences
|
||||
|
||||
def trim_to_tokens(text, token_budget, from_tail=False):
|
||||
if token_budget <= 0 or not text:
|
||||
return ""
|
||||
sentences = split_sentences(text)
|
||||
if not sentences:
|
||||
return ""
|
||||
|
||||
collected = []
|
||||
remaining = token_budget
|
||||
seq = reversed(sentences) if from_tail else sentences
|
||||
for s in seq:
|
||||
tks = num_tokens_from_string(s)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining:
|
||||
collected.append(s)
|
||||
break
|
||||
collected.append(s)
|
||||
remaining -= tks
|
||||
|
||||
if from_tail:
|
||||
collected = list(reversed(collected))
|
||||
return "".join(collected)
|
||||
|
||||
def extract_position(ck):
|
||||
pn = None
|
||||
top = None
|
||||
left = None
|
||||
try:
|
||||
if ck.get("page_num_int"):
|
||||
pn = ck["page_num_int"][0]
|
||||
elif ck.get("page_number") is not None:
|
||||
pn = ck.get("page_number")
|
||||
|
||||
if ck.get("top_int"):
|
||||
top = ck["top_int"][0]
|
||||
elif ck.get("top") is not None:
|
||||
top = ck.get("top")
|
||||
|
||||
if ck.get("position_int"):
|
||||
left = ck["position_int"][0][1]
|
||||
elif ck.get("x0") is not None:
|
||||
left = ck.get("x0")
|
||||
except Exception:
|
||||
pn = top = left = None
|
||||
return pn, top, left
|
||||
|
||||
indexed = list(enumerate(chunks))
|
||||
positioned_indices = []
|
||||
unpositioned_indices = []
|
||||
for idx, ck in indexed:
|
||||
pn, top, left = extract_position(ck)
|
||||
if pn is not None and top is not None:
|
||||
positioned_indices.append((idx, pn, top, left if left is not None else 0))
|
||||
else:
|
||||
unpositioned_indices.append(idx)
|
||||
|
||||
if positioned_indices:
|
||||
positioned_indices.sort(key=lambda x: (int(x[1]), int(x[2]), int(x[3]), x[0]))
|
||||
ordered_indices = [i for i, _, _, _ in positioned_indices] + unpositioned_indices
|
||||
else:
|
||||
ordered_indices = [idx for idx, _ in indexed]
|
||||
|
||||
total = len(ordered_indices)
|
||||
for sorted_pos, idx in enumerate(ordered_indices):
|
||||
ck = chunks[idx]
|
||||
token_budget = image_context_size if is_image_chunk(ck) else table_context_size if is_table_chunk(ck) else 0
|
||||
if token_budget <= 0:
|
||||
continue
|
||||
|
||||
prev_ctx = []
|
||||
remaining_prev = token_budget
|
||||
for prev_idx in range(sorted_pos - 1, -1, -1):
|
||||
if remaining_prev <= 0:
|
||||
break
|
||||
neighbor_idx = ordered_indices[prev_idx]
|
||||
if not is_text_chunk(chunks[neighbor_idx]):
|
||||
break
|
||||
txt = get_text(chunks[neighbor_idx])
|
||||
if not txt:
|
||||
continue
|
||||
tks = num_tokens_from_string(txt)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining_prev:
|
||||
txt = trim_to_tokens(txt, remaining_prev, from_tail=True)
|
||||
tks = num_tokens_from_string(txt)
|
||||
prev_ctx.append(txt)
|
||||
remaining_prev -= tks
|
||||
prev_ctx.reverse()
|
||||
|
||||
next_ctx = []
|
||||
remaining_next = token_budget
|
||||
for next_idx in range(sorted_pos + 1, total):
|
||||
if remaining_next <= 0:
|
||||
break
|
||||
neighbor_idx = ordered_indices[next_idx]
|
||||
if not is_text_chunk(chunks[neighbor_idx]):
|
||||
break
|
||||
txt = get_text(chunks[neighbor_idx])
|
||||
if not txt:
|
||||
continue
|
||||
tks = num_tokens_from_string(txt)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining_next:
|
||||
txt = trim_to_tokens(txt, remaining_next, from_tail=False)
|
||||
tks = num_tokens_from_string(txt)
|
||||
next_ctx.append(txt)
|
||||
remaining_next -= tks
|
||||
|
||||
if not prev_ctx and not next_ctx:
|
||||
continue
|
||||
|
||||
self_text = get_text(ck)
|
||||
pieces = [*prev_ctx]
|
||||
if self_text:
|
||||
pieces.append(self_text)
|
||||
pieces.extend(next_ctx)
|
||||
combined = "\n".join(pieces)
|
||||
|
||||
original = ck.get("content_with_weight")
|
||||
if "content_with_weight" in ck:
|
||||
ck["content_with_weight"] = combined
|
||||
elif "text" in ck:
|
||||
original = ck.get("text")
|
||||
ck["text"] = combined
|
||||
|
||||
if combined != original:
|
||||
if "content_ltks" in ck:
|
||||
ck["content_ltks"] = rag_tokenizer.tokenize(combined)
|
||||
if "content_sm_ltks" in ck:
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
|
||||
if positioned_indices:
|
||||
chunks[:] = [chunks[i] for i in ordered_indices]
|
||||
|
||||
return chunks
|
||||
|
||||
|
||||
def add_positions(d, poss):
|
||||
if not poss:
|
||||
return
|
||||
|
|
|
|||
|
|
@ -424,6 +424,7 @@ class Dealer:
|
|||
|
||||
sim_np = np.array(sim, dtype=np.float64)
|
||||
if sim_np.size == 0:
|
||||
ranks["doc_aggs"] = []
|
||||
return ranks
|
||||
|
||||
sorted_idx = np.argsort(sim_np * -1)
|
||||
|
|
@ -433,6 +434,7 @@ class Dealer:
|
|||
ranks["total"] = int(filtered_count)
|
||||
|
||||
if filtered_count == 0:
|
||||
ranks["doc_aggs"] = []
|
||||
return ranks
|
||||
|
||||
max_pages = max(RERANK_LIMIT // max(page_size, 1), 1)
|
||||
|
|
|
|||
|
|
@ -41,6 +41,7 @@ from common.data_source import BlobStorageConnector, NotionConnector, DiscordCon
|
|||
from common.constants import FileSource, TaskStatus
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.confluence_connector import ConfluenceConnector
|
||||
from common.data_source.gmail_connector import GmailConnector
|
||||
from common.data_source.interfaces import CheckpointOutputWrapper
|
||||
from common.data_source.utils import load_all_docs_from_checkpoint_connector
|
||||
from common.log_utils import init_root_logger
|
||||
|
|
@ -75,8 +76,9 @@ class SyncBase:
|
|||
min_update = min([doc.doc_updated_at for doc in document_batch])
|
||||
max_update = max([doc.doc_updated_at for doc in document_batch])
|
||||
next_update = max([next_update, max_update])
|
||||
docs = [
|
||||
{
|
||||
docs = []
|
||||
for doc in document_batch:
|
||||
doc_dict = {
|
||||
"id": doc.id,
|
||||
"connector_id": task["connector_id"],
|
||||
"source": self.SOURCE_NAME,
|
||||
|
|
@ -86,8 +88,10 @@ class SyncBase:
|
|||
"doc_updated_at": doc.doc_updated_at,
|
||||
"blob": doc.blob,
|
||||
}
|
||||
for doc in document_batch
|
||||
]
|
||||
# Add metadata if present
|
||||
if doc.metadata:
|
||||
doc_dict["metadata"] = doc.metadata
|
||||
docs.append(doc_dict)
|
||||
|
||||
try:
|
||||
e, kb = KnowledgebaseService.get_by_id(task["kb_id"])
|
||||
|
|
@ -227,7 +231,64 @@ class Gmail(SyncBase):
|
|||
SOURCE_NAME: str = FileSource.GMAIL
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
pass
|
||||
# Gmail sync reuses the generic LoadConnector/PollConnector interface
|
||||
# implemented by common.data_source.gmail_connector.GmailConnector.
|
||||
#
|
||||
# Config expectations (self.conf):
|
||||
# credentials: Gmail / Workspace OAuth JSON (with primary admin email)
|
||||
# batch_size: optional, defaults to INDEX_BATCH_SIZE
|
||||
batch_size = self.conf.get("batch_size", INDEX_BATCH_SIZE)
|
||||
|
||||
self.connector = GmailConnector(batch_size=batch_size)
|
||||
|
||||
credentials = self.conf.get("credentials")
|
||||
if not credentials:
|
||||
raise ValueError("Gmail connector is missing credentials.")
|
||||
|
||||
new_credentials = self.connector.load_credentials(credentials)
|
||||
if new_credentials:
|
||||
# Persist rotated / refreshed credentials back to connector config
|
||||
try:
|
||||
updated_conf = copy.deepcopy(self.conf)
|
||||
updated_conf["credentials"] = new_credentials
|
||||
ConnectorService.update_by_id(task["connector_id"], {"config": updated_conf})
|
||||
self.conf = updated_conf
|
||||
logging.info(
|
||||
"Persisted refreshed Gmail credentials for connector %s",
|
||||
task["connector_id"],
|
||||
)
|
||||
except Exception:
|
||||
logging.exception(
|
||||
"Failed to persist refreshed Gmail credentials for connector %s",
|
||||
task["connector_id"],
|
||||
)
|
||||
|
||||
# Decide between full reindex and incremental polling by time range.
|
||||
if task["reindex"] == "1" or not task.get("poll_range_start"):
|
||||
start_time = None
|
||||
end_time = None
|
||||
begin_info = "totally"
|
||||
document_generator = self.connector.load_from_state()
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
# Defensive: if poll_start is somehow None, fall back to full load
|
||||
if poll_start is None:
|
||||
start_time = None
|
||||
end_time = None
|
||||
begin_info = "totally"
|
||||
document_generator = self.connector.load_from_state()
|
||||
else:
|
||||
start_time = poll_start.timestamp()
|
||||
end_time = datetime.now(timezone.utc).timestamp()
|
||||
begin_info = f"from {poll_start}"
|
||||
document_generator = self.connector.poll_source(start_time, end_time)
|
||||
|
||||
try:
|
||||
admin_email = self.connector.primary_admin_email
|
||||
except RuntimeError:
|
||||
admin_email = "unknown"
|
||||
logging.info(f"Connect to Gmail as {admin_email} {begin_info}")
|
||||
return document_generator
|
||||
|
||||
|
||||
class Dropbox(SyncBase):
|
||||
|
|
|
|||
|
|
@ -69,7 +69,7 @@ def convert_matching_field(field_weightstr: str) -> str:
|
|||
if field == "docnm_kwd" or field == "title_tks":
|
||||
field = "docnm@ft_docnm_rag_coarse"
|
||||
elif field == "title_sm_tks":
|
||||
field = "docnm@ft_title_rag_fine"
|
||||
field = "docnm@ft_docnm_rag_fine"
|
||||
elif field == "important_kwd":
|
||||
field = "important_keywords@ft_important_keywords_rag_coarse"
|
||||
elif field == "important_tks":
|
||||
|
|
|
|||
|
|
@ -42,6 +42,8 @@ DEFAULT_PARSER_CONFIG = {
|
|||
"auto_keywords": 0,
|
||||
"auto_questions": 0,
|
||||
"html4excel": False,
|
||||
"image_context_size": 0,
|
||||
"table_context_size": 0,
|
||||
"topn_tags": 3,
|
||||
"raptor": {
|
||||
"use_raptor": True,
|
||||
|
|
@ -62,4 +64,4 @@ DEFAULT_PARSER_CONFIG = {
|
|||
],
|
||||
"method": "light",
|
||||
},
|
||||
}
|
||||
}
|
||||
|
|
|
|||
7
web/src/assets/svg/data-source/gmail.svg
Normal file
7
web/src/assets/svg/data-source/gmail.svg
Normal file
{kind=link}
|
|
@ -0,0 +1,7 @@
|
|||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="52 42 88 66">
|
||||
<path fill="#4285f4" d="M58 108h14V74L52 59v43c0 3.32 2.69 6 6 6"/>
|
||||
<path fill="#34a853" d="M120 108h14c3.32 0 6-2.69 6-6V59l-20 15"/>
|
||||
<path fill="#fbbc04" d="M120 48v26l20-15v-8c0-7.42-8.47-11.65-14.4-7.2"/>
|
||||
<path fill="#ea4335" d="M72 74V48l24 18 24-18v26L96 92"/>
|
||||
<path fill="#c5221f" d="M52 51v8l20 15V48l-5.6-4.2c-5.94-4.45-14.4-.22-14.4 7.2"/>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 419 B |
18
web/src/components/bool-segmented.tsx
Normal file
18
web/src/components/bool-segmented.tsx
Normal file
|
|
@ -0,0 +1,18 @@
|
|||
import { omit } from 'lodash';
|
||||
import { Segmented, SegmentedProps } from './ui/segmented';
|
||||
|
||||
export function BoolSegmented({ ...props }: Omit<SegmentedProps, 'options'>) {
|
||||
return (
|
||||
<Segmented
|
||||
options={
|
||||
[
|
||||
{ value: true, label: 'True' },
|
||||
{ value: false, label: 'False' },
|
||||
] as any
|
||||
}
|
||||
sizeType="sm"
|
||||
itemClassName="justify-center flex-1"
|
||||
{...omit(props, 'options')}
|
||||
></Segmented>
|
||||
);
|
||||
}
|
||||
|
|
@ -6,7 +6,9 @@ import {
|
|||
} from '@/hooks/document-hooks';
|
||||
import { IReference, IReferenceChunk } from '@/interfaces/database/chat';
|
||||
import {
|
||||
currentReg,
|
||||
preprocessLaTeX,
|
||||
replaceTextByOldReg,
|
||||
replaceThinkToSection,
|
||||
showImage,
|
||||
} from '@/utils/chat';
|
||||
|
|
@ -32,7 +34,6 @@ import rehypeRaw from 'rehype-raw';
|
|||
import remarkGfm from 'remark-gfm';
|
||||
import remarkMath from 'remark-math';
|
||||
import { visitParents } from 'unist-util-visit-parents';
|
||||
import { currentReg, replaceTextByOldReg } from '../pages/next-chats/utils';
|
||||
import styles from './floating-chat-widget-markdown.less';
|
||||
import { useIsDarkTheme } from './theme-provider';
|
||||
|
||||
|
|
|
|||
24
web/src/components/logical-operator.tsx
Normal file
24
web/src/components/logical-operator.tsx
Normal file
|
|
@ -0,0 +1,24 @@
|
|||
import { useBuildSwitchLogicOperatorOptions } from '@/hooks/logic-hooks/use-build-options';
|
||||
import { RAGFlowFormItem } from './ragflow-form';
|
||||
import { RAGFlowSelect } from './ui/select';
|
||||
|
||||
type LogicalOperatorProps = { name: string };
|
||||
|
||||
export function LogicalOperator({ name }: LogicalOperatorProps) {
|
||||
const switchLogicOperatorOptions = useBuildSwitchLogicOperatorOptions();
|
||||
|
||||
return (
|
||||
<div className="relative min-w-14">
|
||||
<RAGFlowFormItem
|
||||
name={name}
|
||||
className="absolute top-1/2 -translate-y-1/2 right-1 left-0 z-10 bg-bg-base"
|
||||
>
|
||||
<RAGFlowSelect
|
||||
options={switchLogicOperatorOptions}
|
||||
triggerClassName="w-full text-xs px-1 py-0 h-6"
|
||||
></RAGFlowSelect>
|
||||
</RAGFlowFormItem>
|
||||
<div className="absolute border-l border-y w-5 right-0 top-4 bottom-4 rounded-l-lg"></div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
|
|
@ -21,11 +21,12 @@ import { useTranslation } from 'react-i18next';
|
|||
import 'katex/dist/katex.min.css'; // `rehype-katex` does not import the CSS for you
|
||||
|
||||
import {
|
||||
currentReg,
|
||||
preprocessLaTeX,
|
||||
replaceTextByOldReg,
|
||||
replaceThinkToSection,
|
||||
showImage,
|
||||
} from '@/utils/chat';
|
||||
import { currentReg, replaceTextByOldReg } from '../utils';
|
||||
|
||||
import classNames from 'classnames';
|
||||
import { omit } from 'lodash';
|
||||
|
|
@ -1,6 +1,10 @@
|
|||
import { ReactComponent as AssistantIcon } from '@/assets/svg/assistant.svg';
|
||||
import { MessageType } from '@/constants/chat';
|
||||
import { IReference, IReferenceChunk } from '@/interfaces/database/chat';
|
||||
import {
|
||||
IMessage,
|
||||
IReference,
|
||||
IReferenceChunk,
|
||||
} from '@/interfaces/database/chat';
|
||||
import classNames from 'classnames';
|
||||
import { memo, useCallback, useEffect, useMemo } from 'react';
|
||||
|
||||
|
|
@ -10,9 +14,8 @@ import {
|
|||
} from '@/hooks/document-hooks';
|
||||
import { IRegenerateMessage, IRemoveMessageById } from '@/hooks/logic-hooks';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { IMessage } from '@/pages/chat/interface';
|
||||
import MarkdownContent from '@/pages/chat/markdown-content';
|
||||
import { Avatar, Flex, Space } from 'antd';
|
||||
import MarkdownContent from '../markdown-content';
|
||||
import { ReferenceDocumentList } from '../next-message-item/reference-document-list';
|
||||
import { InnerUploadedMessageFiles } from '../next-message-item/uploaded-message-files';
|
||||
import { useTheme } from '../theme-provider';
|
||||
|
|
|
|||
|
|
@ -17,15 +17,13 @@ import { Input } from '@/components/ui/input';
|
|||
import { Separator } from '@/components/ui/separator';
|
||||
import { SwitchLogicOperator, SwitchOperatorOptions } from '@/constants/agent';
|
||||
import { useBuildSwitchOperatorOptions } from '@/hooks/logic-hooks/use-build-operator-options';
|
||||
import { useBuildSwitchLogicOperatorOptions } from '@/hooks/logic-hooks/use-build-options';
|
||||
import { useFetchKnowledgeMetadata } from '@/hooks/use-knowledge-request';
|
||||
import { PromptEditor } from '@/pages/agent/form/components/prompt-editor';
|
||||
import { Plus, X } from 'lucide-react';
|
||||
import { useCallback } from 'react';
|
||||
import { useFieldArray, useFormContext } from 'react-hook-form';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { RAGFlowFormItem } from '../ragflow-form';
|
||||
import { RAGFlowSelect } from '../ui/select';
|
||||
import { LogicalOperator } from '../logical-operator';
|
||||
|
||||
export function MetadataFilterConditions({
|
||||
kbIds,
|
||||
|
|
@ -44,8 +42,6 @@ export function MetadataFilterConditions({
|
|||
|
||||
const switchOperatorOptions = useBuildSwitchOperatorOptions();
|
||||
|
||||
const switchLogicOperatorOptions = useBuildSwitchLogicOperatorOptions();
|
||||
|
||||
const { fields, remove, append } = useFieldArray({
|
||||
name,
|
||||
control: form.control,
|
||||
|
|
@ -53,14 +49,16 @@ export function MetadataFilterConditions({
|
|||
|
||||
const add = useCallback(
|
||||
(key: string) => () => {
|
||||
form.setValue(logic, SwitchLogicOperator.And);
|
||||
if (fields.length === 1) {
|
||||
form.setValue(logic, SwitchLogicOperator.And);
|
||||
}
|
||||
append({
|
||||
key,
|
||||
value: '',
|
||||
op: SwitchOperatorOptions[0].value,
|
||||
});
|
||||
},
|
||||
[append, form, logic],
|
||||
[append, fields.length, form, logic],
|
||||
);
|
||||
|
||||
return (
|
||||
|
|
@ -85,20 +83,7 @@ export function MetadataFilterConditions({
|
|||
</DropdownMenu>
|
||||
</div>
|
||||
<section className="flex">
|
||||
{fields.length > 1 && (
|
||||
<div className="relative min-w-14">
|
||||
<RAGFlowFormItem
|
||||
name={logic}
|
||||
className="absolute top-1/2 -translate-y-1/2 right-1 left-0 z-10 bg-bg-base"
|
||||
>
|
||||
<RAGFlowSelect
|
||||
options={switchLogicOperatorOptions}
|
||||
triggerClassName="w-full text-xs px-1 py-0 h-6"
|
||||
></RAGFlowSelect>
|
||||
</RAGFlowFormItem>
|
||||
<div className="absolute border-l border-y w-5 right-0 top-4 bottom-4 rounded-l-lg"></div>
|
||||
</div>
|
||||
)}
|
||||
{fields.length > 1 && <LogicalOperator name={logic}></LogicalOperator>}
|
||||
<div className="space-y-5 flex-1">
|
||||
{fields.map((field, index) => {
|
||||
const typeField = `${name}.${index}.key`;
|
||||
|
|
|
|||
|
|
@ -19,13 +19,14 @@ import { useTranslation } from 'react-i18next';
|
|||
import 'katex/dist/katex.min.css'; // `rehype-katex` does not import the CSS for you
|
||||
|
||||
import {
|
||||
currentReg,
|
||||
preprocessLaTeX,
|
||||
replaceTextByOldReg,
|
||||
replaceThinkToSection,
|
||||
showImage,
|
||||
} from '@/utils/chat';
|
||||
|
||||
import { cn } from '@/lib/utils';
|
||||
import { currentReg, replaceTextByOldReg } from '@/pages/chat/utils';
|
||||
import classNames from 'classnames';
|
||||
import { omit } from 'lodash';
|
||||
import { pipe } from 'lodash/fp';
|
||||
|
|
|
|||
|
|
@ -1,6 +1,10 @@
|
|||
import { ReactComponent as AssistantIcon } from '@/assets/svg/assistant.svg';
|
||||
import { MessageType } from '@/constants/chat';
|
||||
import { IReferenceChunk, IReferenceObject } from '@/interfaces/database/chat';
|
||||
import {
|
||||
IMessage,
|
||||
IReferenceChunk,
|
||||
IReferenceObject,
|
||||
} from '@/interfaces/database/chat';
|
||||
import classNames from 'classnames';
|
||||
import {
|
||||
PropsWithChildren,
|
||||
|
|
@ -17,7 +21,6 @@ import { INodeEvent, MessageEventType } from '@/hooks/use-send-message';
|
|||
import { cn } from '@/lib/utils';
|
||||
import { AgentChatContext } from '@/pages/agent/context';
|
||||
import { WorkFlowTimeline } from '@/pages/agent/log-sheet/workflow-timeline';
|
||||
import { IMessage } from '@/pages/chat/interface';
|
||||
import { downloadFile } from '@/services/file-manager-service';
|
||||
import { downloadFileFromBlob } from '@/utils/file-util';
|
||||
import { isEmpty } from 'lodash';
|
||||
|
|
|
|||
|
|
@ -5,8 +5,8 @@ import {
|
|||
DialogHeader,
|
||||
DialogTitle,
|
||||
} from '@/components/ui/dialog';
|
||||
import { TagRenameId } from '@/constants/knowledge';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { TagRenameId } from '@/pages/add-knowledge/constant';
|
||||
import { ReactNode } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { ButtonLoading } from '../ui/button';
|
||||
|
|
|
|||
|
|
@ -13,8 +13,8 @@ import {
|
|||
FormMessage,
|
||||
} from '@/components/ui/form';
|
||||
import { Input } from '@/components/ui/input';
|
||||
import { TagRenameId } from '@/constants/knowledge';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { TagRenameId } from '@/pages/add-knowledge/constant';
|
||||
import { useEffect } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
|
||||
|
|
|
|||
|
|
@ -75,7 +75,6 @@ export enum Operator {
|
|||
Message = 'Message',
|
||||
Relevant = 'Relevant',
|
||||
RewriteQuestion = 'RewriteQuestion',
|
||||
KeywordExtract = 'KeywordExtract',
|
||||
DuckDuckGo = 'DuckDuckGo',
|
||||
Wikipedia = 'Wikipedia',
|
||||
PubMed = 'PubMed',
|
||||
|
|
@ -84,14 +83,10 @@ export enum Operator {
|
|||
Bing = 'Bing',
|
||||
GoogleScholar = 'GoogleScholar',
|
||||
GitHub = 'GitHub',
|
||||
QWeather = 'QWeather',
|
||||
ExeSQL = 'ExeSQL',
|
||||
Switch = 'Switch',
|
||||
WenCai = 'WenCai',
|
||||
AkShare = 'AkShare',
|
||||
YahooFinance = 'YahooFinance',
|
||||
Jin10 = 'Jin10',
|
||||
TuShare = 'TuShare',
|
||||
Note = 'Note',
|
||||
Crawler = 'Crawler',
|
||||
Invoke = 'Invoke',
|
||||
|
|
@ -118,6 +113,9 @@ export enum Operator {
|
|||
Splitter = 'Splitter',
|
||||
HierarchicalMerger = 'HierarchicalMerger',
|
||||
Extractor = 'Extractor',
|
||||
Loop = 'Loop',
|
||||
LoopStart = 'LoopItem',
|
||||
ExitLoop = 'ExitLoop',
|
||||
}
|
||||
|
||||
export enum ComparisonOperator {
|
||||
|
|
|
|||
|
|
@ -92,3 +92,5 @@ export enum DocumentParserType {
|
|||
Tag = 'tag',
|
||||
KnowledgeGraph = 'knowledge_graph',
|
||||
}
|
||||
|
||||
export const TagRenameId = 'tagRename';
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
import { ChatSearchParams } from '@/constants/chat';
|
||||
import {
|
||||
IClientConversation,
|
||||
IConversation,
|
||||
IDialog,
|
||||
IStats,
|
||||
|
|
@ -10,8 +11,7 @@ import {
|
|||
IFeedbackRequestBody,
|
||||
} from '@/interfaces/request/chat';
|
||||
import i18n from '@/locales/config';
|
||||
import { IClientConversation } from '@/pages/chat/interface';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/chat/shared-hooks';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/next-chats/hooks/use-send-shared-message';
|
||||
import chatService from '@/services/chat-service';
|
||||
import {
|
||||
buildMessageListWithUuid,
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
import { DSL, IFlow } from '@/interfaces/database/flow';
|
||||
import { IDebugSingleRequestBody } from '@/interfaces/request/flow';
|
||||
import i18n from '@/locales/config';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/chat/shared-hooks';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/next-chats/hooks/use-send-shared-message';
|
||||
import flowService from '@/services/flow-service';
|
||||
import { buildMessageListWithUuid } from '@/utils/chat';
|
||||
import { useMutation, useQuery, useQueryClient } from '@tanstack/react-query';
|
||||
|
|
|
|||
|
|
@ -2,9 +2,13 @@ import { Authorization } from '@/constants/authorization';
|
|||
import { MessageType } from '@/constants/chat';
|
||||
import { LanguageTranslationMap } from '@/constants/common';
|
||||
import { ResponseType } from '@/interfaces/database/base';
|
||||
import { IAnswer, Message } from '@/interfaces/database/chat';
|
||||
import {
|
||||
IAnswer,
|
||||
IClientConversation,
|
||||
IMessage,
|
||||
Message,
|
||||
} from '@/interfaces/database/chat';
|
||||
import { IKnowledgeFile } from '@/interfaces/database/knowledge';
|
||||
import { IClientConversation, IMessage } from '@/pages/chat/interface';
|
||||
import api from '@/utils/api';
|
||||
import { getAuthorization } from '@/utils/authorization-util';
|
||||
import { buildMessageUuid } from '@/utils/chat';
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ import { IDebugSingleRequestBody } from '@/interfaces/request/agent';
|
|||
import i18n from '@/locales/config';
|
||||
import { BeginId } from '@/pages/agent/constant';
|
||||
import { IInputs } from '@/pages/agent/interface';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/chat/shared-hooks';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/next-chats/hooks/use-send-shared-message';
|
||||
import agentService, {
|
||||
fetchAgentLogsByCanvasId,
|
||||
fetchPipeLineList,
|
||||
|
|
|
|||
|
|
@ -2,12 +2,12 @@ import { FileUploadProps } from '@/components/file-upload';
|
|||
import message from '@/components/ui/message';
|
||||
import { ChatSearchParams } from '@/constants/chat';
|
||||
import {
|
||||
IClientConversation,
|
||||
IConversation,
|
||||
IDialog,
|
||||
IExternalChatInfo,
|
||||
} from '@/interfaces/database/chat';
|
||||
import { IAskRequestBody } from '@/interfaces/request/chat';
|
||||
import { IClientConversation } from '@/pages/next-chats/chat/interface';
|
||||
import { useGetSharedChatSearchParams } from '@/pages/next-chats/hooks/use-send-shared-message';
|
||||
import { isConversationIdExist } from '@/pages/next-chats/utils';
|
||||
import chatService from '@/services/next-chat-service';
|
||||
|
|
|
|||
|
|
@ -183,3 +183,12 @@ export interface IExternalChatInfo {
|
|||
title: string;
|
||||
prologue?: string;
|
||||
}
|
||||
|
||||
export interface IMessage extends Message {
|
||||
id: string;
|
||||
reference?: IReference; // the latest news has reference
|
||||
}
|
||||
|
||||
export interface IClientConversation extends IConversation {
|
||||
message: IMessage[];
|
||||
}
|
||||
|
|
|
|||
|
|
@ -739,6 +739,7 @@ Example: Virtual Hosted Style`,
|
|||
'Sync pages and databases from Notion for knowledge retrieval.',
|
||||
google_driveDescription:
|
||||
'Connect your Google Drive via OAuth and sync specific folders or drives.',
|
||||
gmailDescription: 'Connect your Gmail via OAuth to sync emails.',
|
||||
webdavDescription: 'Connect to WebDAV servers to sync files.',
|
||||
webdavRemotePathTip:
|
||||
'Optional: Specify a folder path on the WebDAV server (e.g., /Documents). Leave empty to sync from root.',
|
||||
|
|
@ -750,6 +751,10 @@ Example: Virtual Hosted Style`,
|
|||
'Comma-separated emails whose "My Drive" contents should be indexed (include the primary admin).',
|
||||
google_driveSharedFoldersTip:
|
||||
'Comma-separated Google Drive folder links to crawl.',
|
||||
gmailPrimaryAdminTip:
|
||||
'Primary admin email with Gmail / Workspace access, used to enumerate domain users and as the default sync account.',
|
||||
gmailTokenTip:
|
||||
'Upload the OAuth JSON generated from Google Console. If it only contains client credentials, run the browser-based verification once to mint long-lived refresh tokens.',
|
||||
dropboxDescription:
|
||||
'Connect your Dropbox to sync files and folders from a chosen account.',
|
||||
dropboxAccessTokenTip:
|
||||
|
|
@ -1170,8 +1175,13 @@ Example: Virtual Hosted Style`,
|
|||
addField: 'Add option',
|
||||
addMessage: 'Add message',
|
||||
loop: 'Loop',
|
||||
loopTip:
|
||||
loopDescription:
|
||||
'Loop is the upper limit of the number of loops of the current component, when the number of loops exceeds the value of loop, it means that the component can not complete the current task, please re-optimize agent',
|
||||
exitLoop: 'Exit loop',
|
||||
exitLoopDescription: `Equivalent to "break". This node has no configuration items. When the loop body reaches this node, the loop terminates.`,
|
||||
loopVariables: 'Loop Variables',
|
||||
maximumLoopCount: 'Maximum loop count',
|
||||
loopTerminationCondition: 'Loop termination condition',
|
||||
yes: 'Yes',
|
||||
no: 'No',
|
||||
key: 'Key',
|
||||
|
|
@ -1655,9 +1665,8 @@ This delimiter is used to split the input text into several text pieces echo of
|
|||
variableAssignerDescription:
|
||||
'This component performs operations on Data objects, including extracting, filtering, and editing keys and values in the Data.',
|
||||
variableAggregator: 'Variable aggregator',
|
||||
variableAggregatorDescription: `This process aggregates variables from multiple branches into a single variable to achieve unified configuration for downstream nodes.
|
||||
|
||||
The variable aggregation node (originally the variable assignment node) is a crucial node in the workflow. It is responsible for integrating the output results of different branches, ensuring that regardless of which branch is executed, its result can be referenced and accessed through a unified variable. This is extremely useful in multi-branch scenarios, as it maps variables with the same function across different branches to a single output variable, avoiding redundant definitions in downstream nodes.`,
|
||||
variableAggregatorDescription: `
|
||||
This process aggregates variables from multiple branches into a single variable to achieve unified configuration for downstream nodes.`,
|
||||
inputVariables: 'Input variables',
|
||||
runningHintText: 'is running...🕞',
|
||||
openingSwitch: 'Opening switch',
|
||||
|
|
@ -1886,10 +1895,10 @@ Important structured information may include: names, dates, locations, events, k
|
|||
overwrite: 'Overwritten By',
|
||||
clear: 'Clear',
|
||||
set: 'Set',
|
||||
'+=': 'Add',
|
||||
'-=': 'Subtract',
|
||||
'*=': 'Multiply',
|
||||
'/=': 'Divide',
|
||||
add: 'Add',
|
||||
subtract: 'Subtract',
|
||||
multiply: 'Multiply',
|
||||
divide: 'Divide',
|
||||
append: 'Append',
|
||||
extend: 'Extend',
|
||||
removeFirst: 'Remove first',
|
||||
|
|
|
|||
|
|
@ -736,6 +736,8 @@ export default {
|
|||
'Синхронизируйте страницы и базы данных из Notion для извлечения знаний.',
|
||||
google_driveDescription:
|
||||
'Подключите ваш Google Drive через OAuth и синхронизируйте определенные папки или диски.',
|
||||
gmailDescription:
|
||||
'Подключите ваш Gmail / Google Workspace аккаунт для синхронизации писем и их метаданных, чтобы построить корпоративную почтовую базу знаний и поиск с учетом прав доступа.',
|
||||
google_driveTokenTip:
|
||||
'Загрузите JSON токена OAuth, сгенерированный из помощника OAuth или Google Cloud Console. Вы также можете загрузить client_secret JSON из "установленного" или "веб" приложения. Если это ваша первая синхронизация, откроется окно браузера для завершения согласия OAuth. Если JSON уже содержит токен обновления, он будет автоматически повторно использован.',
|
||||
google_drivePrimaryAdminTip:
|
||||
|
|
@ -744,6 +746,10 @@ export default {
|
|||
'Электронные почты через запятую, чье содержимое "Мой диск" должно индексироваться (включите основного администратора).',
|
||||
google_driveSharedFoldersTip:
|
||||
'Ссылки на папки Google Drive через запятую для обхода.',
|
||||
gmailPrimaryAdminTip:
|
||||
'Основной административный email с доступом к Gmail / Workspace, используется для перечисления пользователей домена и как аккаунт синхронизации по умолчанию.',
|
||||
gmailTokenTip:
|
||||
'Загрузите OAuth JSON, сгенерированный в Google Console. Если он содержит только учетные данные клиента, выполните одноразовое подтверждение в браузере, чтобы получить долгоживущие токены обновления.',
|
||||
jiraDescription:
|
||||
'Подключите ваше рабочее пространство Jira для синхронизации задач, комментариев и вложений.',
|
||||
jiraBaseUrlTip:
|
||||
|
|
|
|||
|
|
@ -718,6 +718,7 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
|||
notionDescription: ' 同步 Notion 页面与数据库,用于知识检索。',
|
||||
google_driveDescription:
|
||||
'通过 OAuth 连接 Google Drive,并同步指定的文件夹或云端硬盘。',
|
||||
gmailDescription: '通过 OAuth 连接 Gmail,用于同步邮件。',
|
||||
google_driveTokenTip:
|
||||
'请上传由 OAuth helper 或 Google Cloud Console 导出的 OAuth token JSON。也支持上传 “installed” 或 “web” 类型的 client_secret JSON。若为首次同步,将自动弹出浏览器完成 OAuth 授权流程;如果该 JSON 已包含 refresh token,将会被自动复用。',
|
||||
google_drivePrimaryAdminTip: '拥有相应 Drive 访问权限的管理员邮箱。',
|
||||
|
|
@ -725,6 +726,10 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
|||
'需要索引其 “我的云端硬盘” 的邮箱,多个邮箱用逗号分隔(建议包含管理员)。',
|
||||
google_driveSharedFoldersTip:
|
||||
'需要同步的 Google Drive 文件夹链接,多个链接用逗号分隔。',
|
||||
gmailPrimaryAdminTip:
|
||||
'拥有 Gmail / Workspace 访问权限的主要管理员邮箱,用于列出域内用户并作为默认同步账号。',
|
||||
gmailTokenTip:
|
||||
'请上传由 Google Console 生成的 OAuth JSON。如果仅包含 client credentials,请通过浏览器授权一次以获取长期有效的刷新 Token。',
|
||||
dropboxDescription: '连接 Dropbox,同步指定账号下的文件与文件夹。',
|
||||
dropboxAccessTokenTip:
|
||||
'请在 Dropbox App Console 生成 Access Token,并勾选 files.metadata.read、files.content.read、sharing.read 等必要权限。',
|
||||
|
|
@ -1102,9 +1107,14 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
|||
messageMsg: '请输入消息或删除此字段。',
|
||||
addField: '新增字段',
|
||||
addMessage: '新增消息',
|
||||
loop: '循环上限',
|
||||
loopTip:
|
||||
loop: '循环',
|
||||
loopDescription:
|
||||
'loop为当前组件循环次数上限,当循环次数超过loop的值时,说明组件不能完成当前任务,请重新优化agent',
|
||||
exitLoop: '退出循环',
|
||||
exitLoopDescription: `等同于 "break"。此节点没有配置项。当循环体到达此节点时,循环终止。`,
|
||||
loopVariables: '循环变量',
|
||||
maximumLoopCount: '最大循环次数',
|
||||
loopTerminationCondition: '循环终止条件',
|
||||
yes: '是',
|
||||
no: '否',
|
||||
key: '键',
|
||||
|
|
@ -1499,7 +1509,7 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
|||
contentTip: 'content: 邮件内容(可选)',
|
||||
jsonUploadTypeErrorMessage: '请上传json文件',
|
||||
jsonUploadContentErrorMessage: 'json 文件错误',
|
||||
iteration: '循环',
|
||||
iteration: '迭代',
|
||||
iterationDescription: `该组件负责迭代生成新的内容,对列表对象执行多次步骤直至输出所有结果。`,
|
||||
delimiterTip: `该分隔符用于将输入文本分割成几个文本片段,每个文本片段的回显将作为每次迭代的输入项。`,
|
||||
delimiterOptions: {
|
||||
|
|
@ -1545,8 +1555,7 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
|||
variableAssignerDescription:
|
||||
'此组件对数据对象执行操作,包括提取、筛选和编辑数据中的键和值。',
|
||||
variableAggregator: '变量聚合',
|
||||
variableAggregatorDescription: `将多路分支的变量聚合为一个变量,以实现下游节点统一配置。
|
||||
变量聚合节点(原变量赋值节点)是工作流程中的一个关键节点,它负责整合不同分支的输出结果,确保无论哪个分支被执行,其结果都能通过一个统一的变量来引用和访问。这在多分支的情况下非常有用,可将不同分支下相同作用的变量映射为一个输出变量,避免下游节点重复定义。`,
|
||||
variableAggregatorDescription: `该过程将来自多个分支的变量聚合到一个变量中,以实现下游节点的统一配置。`,
|
||||
inputVariables: '输入变量',
|
||||
addVariable: '新增变量',
|
||||
runningHintText: '正在运行中...🕞',
|
||||
|
|
@ -1891,5 +1900,16 @@ Tokenizer 会根据所选方式将内容存储为对应的数据结构。`,
|
|||
searchTitle: '尚未创建搜索应用',
|
||||
addNow: '立即添加',
|
||||
},
|
||||
|
||||
deleteModal: {
|
||||
delAgent: '删除智能体',
|
||||
delDataset: '删除知识库',
|
||||
delSearch: '删除搜索',
|
||||
delFile: '删除文件',
|
||||
delFiles: '删除文件',
|
||||
delFilesContent: '已选择 {{count}} 个文件',
|
||||
delChat: '删除聊天',
|
||||
delMember: '删除成员',
|
||||
},
|
||||
},
|
||||
};
|
||||
|
|
|
|||
|
|
@ -1,34 +0,0 @@
|
|||
.image {
|
||||
width: 100px !important;
|
||||
object-fit: contain;
|
||||
}
|
||||
|
||||
.imagePreview {
|
||||
max-width: 50vw;
|
||||
max-height: 50vh;
|
||||
object-fit: contain;
|
||||
}
|
||||
|
||||
.content {
|
||||
flex: 1;
|
||||
.chunkText;
|
||||
}
|
||||
|
||||
.contentEllipsis {
|
||||
.multipleLineEllipsis(3);
|
||||
}
|
||||
|
||||
.contentText {
|
||||
word-break: break-all !important;
|
||||
}
|
||||
|
||||
.chunkCard {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.cardSelected {
|
||||
background-color: @selectedBackgroundColor;
|
||||
}
|
||||
.cardSelectedDark {
|
||||
background-color: #ffffff2f;
|
||||
}
|
||||
|
|
@ -1,101 +0,0 @@
|
|||
import Image from '@/components/image';
|
||||
import { IChunk } from '@/interfaces/database/knowledge';
|
||||
import { Card, Checkbox, CheckboxProps, Flex, Popover, Switch } from 'antd';
|
||||
import classNames from 'classnames';
|
||||
import DOMPurify from 'dompurify';
|
||||
import { useEffect, useState } from 'react';
|
||||
|
||||
import { useTheme } from '@/components/theme-provider';
|
||||
import { ChunkTextMode } from '../../constant';
|
||||
import styles from './index.less';
|
||||
|
||||
interface IProps {
|
||||
item: IChunk;
|
||||
checked: boolean;
|
||||
switchChunk: (available?: number, chunkIds?: string[]) => void;
|
||||
editChunk: (chunkId: string) => void;
|
||||
handleCheckboxClick: (chunkId: string, checked: boolean) => void;
|
||||
selected: boolean;
|
||||
clickChunkCard: (chunkId: string) => void;
|
||||
textMode: ChunkTextMode;
|
||||
}
|
||||
|
||||
const ChunkCard = ({
|
||||
item,
|
||||
checked,
|
||||
handleCheckboxClick,
|
||||
editChunk,
|
||||
switchChunk,
|
||||
selected,
|
||||
clickChunkCard,
|
||||
textMode,
|
||||
}: IProps) => {
|
||||
const available = Number(item.available_int);
|
||||
const [enabled, setEnabled] = useState(false);
|
||||
const { theme } = useTheme();
|
||||
|
||||
const onChange = (checked: boolean) => {
|
||||
setEnabled(checked);
|
||||
switchChunk(available === 0 ? 1 : 0, [item.chunk_id]);
|
||||
};
|
||||
|
||||
const handleCheck: CheckboxProps['onChange'] = (e) => {
|
||||
handleCheckboxClick(item.chunk_id, e.target.checked);
|
||||
};
|
||||
|
||||
const handleContentDoubleClick = () => {
|
||||
editChunk(item.chunk_id);
|
||||
};
|
||||
|
||||
const handleContentClick = () => {
|
||||
clickChunkCard(item.chunk_id);
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
setEnabled(available === 1);
|
||||
}, [available]);
|
||||
|
||||
return (
|
||||
<Card
|
||||
className={classNames(styles.chunkCard, {
|
||||
[`${theme === 'dark' ? styles.cardSelectedDark : styles.cardSelected}`]:
|
||||
selected,
|
||||
})}
|
||||
>
|
||||
<Flex gap={'middle'} justify={'space-between'}>
|
||||
<Checkbox onChange={handleCheck} checked={checked}></Checkbox>
|
||||
{item.image_id && (
|
||||
<Popover
|
||||
placement="right"
|
||||
content={
|
||||
<Image id={item.image_id} className={styles.imagePreview}></Image>
|
||||
}
|
||||
>
|
||||
<Image id={item.image_id} className={styles.image}></Image>
|
||||
</Popover>
|
||||
)}
|
||||
|
||||
<section
|
||||
onDoubleClick={handleContentDoubleClick}
|
||||
onClick={handleContentClick}
|
||||
className={styles.content}
|
||||
>
|
||||
<div
|
||||
dangerouslySetInnerHTML={{
|
||||
__html: DOMPurify.sanitize(item.content_with_weight),
|
||||
}}
|
||||
className={classNames(styles.contentText, {
|
||||
[styles.contentEllipsis]: textMode === ChunkTextMode.Ellipse,
|
||||
})}
|
||||
></div>
|
||||
</section>
|
||||
|
||||
<div>
|
||||
<Switch checked={enabled} onChange={onChange} />
|
||||
</div>
|
||||
</Flex>
|
||||
</Card>
|
||||
);
|
||||
};
|
||||
|
||||
export default ChunkCard;
|
||||
|
|
@ -1,140 +0,0 @@
|
|||
import EditTag from '@/components/edit-tag';
|
||||
import { useFetchChunk } from '@/hooks/chunk-hooks';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { IChunk } from '@/interfaces/database/knowledge';
|
||||
import { DeleteOutlined } from '@ant-design/icons';
|
||||
import { Divider, Form, Input, Modal, Space, Switch } from 'antd';
|
||||
import React, { useCallback, useEffect, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { useDeleteChunkByIds } from '../../hooks';
|
||||
import {
|
||||
transformTagFeaturesArrayToObject,
|
||||
transformTagFeaturesObjectToArray,
|
||||
} from '../../utils';
|
||||
import { TagFeatureItem } from './tag-feature-item';
|
||||
|
||||
type FieldType = Pick<
|
||||
IChunk,
|
||||
'content_with_weight' | 'tag_kwd' | 'question_kwd' | 'important_kwd'
|
||||
>;
|
||||
|
||||
interface kFProps {
|
||||
doc_id: string;
|
||||
chunkId: string | undefined;
|
||||
parserId: string;
|
||||
}
|
||||
|
||||
const ChunkCreatingModal: React.FC<IModalProps<any> & kFProps> = ({
|
||||
doc_id,
|
||||
chunkId,
|
||||
hideModal,
|
||||
onOk,
|
||||
loading,
|
||||
parserId,
|
||||
}) => {
|
||||
const [form] = Form.useForm();
|
||||
const [checked, setChecked] = useState(false);
|
||||
const { removeChunk } = useDeleteChunkByIds();
|
||||
const { data } = useFetchChunk(chunkId);
|
||||
const { t } = useTranslation();
|
||||
|
||||
const isTagParser = parserId === 'tag';
|
||||
|
||||
const handleOk = useCallback(async () => {
|
||||
try {
|
||||
const values = await form.validateFields();
|
||||
console.log('🚀 ~ handleOk ~ values:', values);
|
||||
|
||||
onOk?.({
|
||||
...values,
|
||||
tag_feas: transformTagFeaturesArrayToObject(values.tag_feas),
|
||||
available_int: checked ? 1 : 0, // available_int
|
||||
});
|
||||
} catch (errorInfo) {
|
||||
console.log('Failed:', errorInfo);
|
||||
}
|
||||
}, [checked, form, onOk]);
|
||||
|
||||
const handleRemove = useCallback(() => {
|
||||
if (chunkId) {
|
||||
return removeChunk([chunkId], doc_id);
|
||||
}
|
||||
}, [chunkId, doc_id, removeChunk]);
|
||||
|
||||
const handleCheck = useCallback(() => {
|
||||
setChecked(!checked);
|
||||
}, [checked]);
|
||||
|
||||
useEffect(() => {
|
||||
if (data?.code === 0) {
|
||||
const { available_int, tag_feas } = data.data;
|
||||
form.setFieldsValue({
|
||||
...(data.data || {}),
|
||||
tag_feas: transformTagFeaturesObjectToArray(tag_feas),
|
||||
});
|
||||
|
||||
setChecked(available_int !== 0);
|
||||
}
|
||||
}, [data, form, chunkId]);
|
||||
|
||||
return (
|
||||
<Modal
|
||||
title={`${chunkId ? t('common.edit') : t('common.create')} ${t('chunk.chunk')}`}
|
||||
open={true}
|
||||
onOk={handleOk}
|
||||
onCancel={hideModal}
|
||||
okButtonProps={{ loading }}
|
||||
destroyOnClose
|
||||
>
|
||||
<Form form={form} autoComplete="off" layout={'vertical'}>
|
||||
<Form.Item<FieldType>
|
||||
label={t('chunk.chunk')}
|
||||
name="content_with_weight"
|
||||
rules={[{ required: true, message: t('chunk.chunkMessage') }]}
|
||||
>
|
||||
<Input.TextArea autoSize={{ minRows: 4, maxRows: 10 }} />
|
||||
</Form.Item>
|
||||
|
||||
<Form.Item<FieldType> label={t('chunk.keyword')} name="important_kwd">
|
||||
<EditTag></EditTag>
|
||||
</Form.Item>
|
||||
<Form.Item<FieldType>
|
||||
label={t('chunk.question')}
|
||||
name="question_kwd"
|
||||
tooltip={t('chunk.questionTip')}
|
||||
>
|
||||
<EditTag></EditTag>
|
||||
</Form.Item>
|
||||
{isTagParser && (
|
||||
<Form.Item<FieldType>
|
||||
label={t('knowledgeConfiguration.tagName')}
|
||||
name="tag_kwd"
|
||||
>
|
||||
<EditTag></EditTag>
|
||||
</Form.Item>
|
||||
)}
|
||||
|
||||
{!isTagParser && <TagFeatureItem></TagFeatureItem>}
|
||||
</Form>
|
||||
|
||||
{chunkId && (
|
||||
<section>
|
||||
<Divider></Divider>
|
||||
<Space size={'large'}>
|
||||
<Switch
|
||||
checkedChildren={t('chunk.enabled')}
|
||||
unCheckedChildren={t('chunk.disabled')}
|
||||
onChange={handleCheck}
|
||||
checked={checked}
|
||||
/>
|
||||
|
||||
<span onClick={handleRemove}>
|
||||
<DeleteOutlined /> {t('common.delete')}
|
||||
</span>
|
||||
</Space>
|
||||
</section>
|
||||
)}
|
||||
</Modal>
|
||||
);
|
||||
};
|
||||
export default ChunkCreatingModal;
|
||||
|
|
@ -1,107 +0,0 @@
|
|||
import {
|
||||
useFetchKnowledgeBaseConfiguration,
|
||||
useFetchTagListByKnowledgeIds,
|
||||
} from '@/hooks/knowledge-hooks';
|
||||
import { MinusCircleOutlined, PlusOutlined } from '@ant-design/icons';
|
||||
import { Button, Form, InputNumber, Select } from 'antd';
|
||||
import { useCallback, useEffect, useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { FormListItem } from '../../utils';
|
||||
|
||||
const FieldKey = 'tag_feas';
|
||||
|
||||
export const TagFeatureItem = () => {
|
||||
const form = Form.useFormInstance();
|
||||
const { t } = useTranslation();
|
||||
const { data: knowledgeConfiguration } = useFetchKnowledgeBaseConfiguration();
|
||||
|
||||
const { setKnowledgeIds, list } = useFetchTagListByKnowledgeIds();
|
||||
|
||||
const tagKnowledgeIds = useMemo(() => {
|
||||
return knowledgeConfiguration?.parser_config?.tag_kb_ids ?? [];
|
||||
}, [knowledgeConfiguration?.parser_config?.tag_kb_ids]);
|
||||
|
||||
const options = useMemo(() => {
|
||||
return list.map((x) => ({
|
||||
value: x[0],
|
||||
label: x[0],
|
||||
}));
|
||||
}, [list]);
|
||||
|
||||
const filterOptions = useCallback(
|
||||
(index: number) => {
|
||||
const tags: FormListItem[] = form.getFieldValue(FieldKey) ?? [];
|
||||
|
||||
// Exclude it's own current data
|
||||
const list = tags
|
||||
.filter((x, idx) => x && index !== idx)
|
||||
.map((x) => x.tag);
|
||||
|
||||
// Exclude the selected data from other options from one's own options.
|
||||
return options.filter((x) => !list.some((y) => x.value === y));
|
||||
},
|
||||
[form, options],
|
||||
);
|
||||
|
||||
useEffect(() => {
|
||||
setKnowledgeIds(tagKnowledgeIds);
|
||||
}, [setKnowledgeIds, tagKnowledgeIds]);
|
||||
|
||||
return (
|
||||
<Form.Item label={t('knowledgeConfiguration.tags')}>
|
||||
<Form.List name={FieldKey} initialValue={[]}>
|
||||
{(fields, { add, remove }) => (
|
||||
<>
|
||||
{fields.map(({ key, name, ...restField }) => (
|
||||
<div key={key} className="flex gap-3 items-center">
|
||||
<div className="flex flex-1 gap-8">
|
||||
<Form.Item
|
||||
{...restField}
|
||||
name={[name, 'tag']}
|
||||
rules={[
|
||||
{ required: true, message: t('common.pleaseSelect') },
|
||||
]}
|
||||
className="w-2/3"
|
||||
>
|
||||
<Select
|
||||
showSearch
|
||||
placeholder={t('knowledgeConfiguration.tagName')}
|
||||
options={filterOptions(name)}
|
||||
/>
|
||||
</Form.Item>
|
||||
<Form.Item
|
||||
{...restField}
|
||||
name={[name, 'frequency']}
|
||||
rules={[
|
||||
{ required: true, message: t('common.pleaseInput') },
|
||||
]}
|
||||
>
|
||||
<InputNumber
|
||||
placeholder={t('knowledgeConfiguration.frequency')}
|
||||
max={10}
|
||||
min={0}
|
||||
/>
|
||||
</Form.Item>
|
||||
</div>
|
||||
<MinusCircleOutlined
|
||||
onClick={() => remove(name)}
|
||||
className="mb-6"
|
||||
/>
|
||||
</div>
|
||||
))}
|
||||
<Form.Item>
|
||||
<Button
|
||||
type="dashed"
|
||||
onClick={() => add()}
|
||||
block
|
||||
icon={<PlusOutlined />}
|
||||
>
|
||||
{t('knowledgeConfiguration.addTag')}
|
||||
</Button>
|
||||
</Form.Item>
|
||||
</>
|
||||
)}
|
||||
</Form.List>
|
||||
</Form.Item>
|
||||
);
|
||||
};
|
||||
|
|
@ -1,221 +0,0 @@
|
|||
import { ReactComponent as FilterIcon } from '@/assets/filter.svg';
|
||||
import { KnowledgeRouteKey } from '@/constants/knowledge';
|
||||
import { IChunkListResult, useSelectChunkList } from '@/hooks/chunk-hooks';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { useKnowledgeBaseId } from '@/hooks/knowledge-hooks';
|
||||
import {
|
||||
ArrowLeftOutlined,
|
||||
CheckCircleOutlined,
|
||||
CloseCircleOutlined,
|
||||
DeleteOutlined,
|
||||
DownOutlined,
|
||||
FilePdfOutlined,
|
||||
PlusOutlined,
|
||||
SearchOutlined,
|
||||
} from '@ant-design/icons';
|
||||
import {
|
||||
Button,
|
||||
Checkbox,
|
||||
Flex,
|
||||
Input,
|
||||
Menu,
|
||||
MenuProps,
|
||||
Popover,
|
||||
Radio,
|
||||
RadioChangeEvent,
|
||||
Segmented,
|
||||
SegmentedProps,
|
||||
Space,
|
||||
Typography,
|
||||
} from 'antd';
|
||||
import { useCallback, useMemo, useState } from 'react';
|
||||
import { Link } from 'umi';
|
||||
import { ChunkTextMode } from '../../constant';
|
||||
|
||||
const { Text } = Typography;
|
||||
|
||||
interface IProps
|
||||
extends Pick<
|
||||
IChunkListResult,
|
||||
'searchString' | 'handleInputChange' | 'available' | 'handleSetAvailable'
|
||||
> {
|
||||
checked: boolean;
|
||||
selectAllChunk: (checked: boolean) => void;
|
||||
createChunk: () => void;
|
||||
removeChunk: () => void;
|
||||
switchChunk: (available: number) => void;
|
||||
changeChunkTextMode(mode: ChunkTextMode): void;
|
||||
}
|
||||
|
||||
const ChunkToolBar = ({
|
||||
selectAllChunk,
|
||||
checked,
|
||||
createChunk,
|
||||
removeChunk,
|
||||
switchChunk,
|
||||
changeChunkTextMode,
|
||||
available,
|
||||
handleSetAvailable,
|
||||
searchString,
|
||||
handleInputChange,
|
||||
}: IProps) => {
|
||||
const data = useSelectChunkList();
|
||||
const documentInfo = data?.documentInfo;
|
||||
const knowledgeBaseId = useKnowledgeBaseId();
|
||||
const [isShowSearchBox, setIsShowSearchBox] = useState(false);
|
||||
const { t } = useTranslate('chunk');
|
||||
|
||||
const handleSelectAllCheck = useCallback(
|
||||
(e: any) => {
|
||||
selectAllChunk(e.target.checked);
|
||||
},
|
||||
[selectAllChunk],
|
||||
);
|
||||
|
||||
const handleSearchIconClick = () => {
|
||||
setIsShowSearchBox(true);
|
||||
};
|
||||
|
||||
const handleSearchBlur = () => {
|
||||
if (!searchString?.trim()) {
|
||||
setIsShowSearchBox(false);
|
||||
}
|
||||
};
|
||||
|
||||
const handleDelete = useCallback(() => {
|
||||
removeChunk();
|
||||
}, [removeChunk]);
|
||||
|
||||
const handleEnabledClick = useCallback(() => {
|
||||
switchChunk(1);
|
||||
}, [switchChunk]);
|
||||
|
||||
const handleDisabledClick = useCallback(() => {
|
||||
switchChunk(0);
|
||||
}, [switchChunk]);
|
||||
|
||||
const items: MenuProps['items'] = useMemo(() => {
|
||||
return [
|
||||
{
|
||||
key: '1',
|
||||
label: (
|
||||
<>
|
||||
<Checkbox onChange={handleSelectAllCheck} checked={checked}>
|
||||
<b>{t('selectAll')}</b>
|
||||
</Checkbox>
|
||||
</>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '2',
|
||||
label: (
|
||||
<Space onClick={handleEnabledClick}>
|
||||
<CheckCircleOutlined />
|
||||
<b>{t('enabledSelected')}</b>
|
||||
</Space>
|
||||
),
|
||||
},
|
||||
{
|
||||
key: '3',
|
||||
label: (
|
||||
<Space onClick={handleDisabledClick}>
|
||||
<CloseCircleOutlined />
|
||||
<b>{t('disabledSelected')}</b>
|
||||
</Space>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '4',
|
||||
label: (
|
||||
<Space onClick={handleDelete}>
|
||||
<DeleteOutlined />
|
||||
<b>{t('deleteSelected')}</b>
|
||||
</Space>
|
||||
),
|
||||
},
|
||||
];
|
||||
}, [
|
||||
checked,
|
||||
handleSelectAllCheck,
|
||||
handleDelete,
|
||||
handleEnabledClick,
|
||||
handleDisabledClick,
|
||||
t,
|
||||
]);
|
||||
|
||||
const content = (
|
||||
<Menu style={{ width: 200 }} items={items} selectable={false} />
|
||||
);
|
||||
|
||||
const handleFilterChange = (e: RadioChangeEvent) => {
|
||||
selectAllChunk(false);
|
||||
handleSetAvailable(e.target.value);
|
||||
};
|
||||
|
||||
const filterContent = (
|
||||
<Radio.Group onChange={handleFilterChange} value={available}>
|
||||
<Space direction="vertical">
|
||||
<Radio value={undefined}>{t('all')}</Radio>
|
||||
<Radio value={1}>{t('enabled')}</Radio>
|
||||
<Radio value={0}>{t('disabled')}</Radio>
|
||||
</Space>
|
||||
</Radio.Group>
|
||||
);
|
||||
|
||||
return (
|
||||
<Flex justify="space-between" align="center">
|
||||
<Space size={'middle'}>
|
||||
<Link
|
||||
to={`/knowledge/${KnowledgeRouteKey.Dataset}?id=${knowledgeBaseId}`}
|
||||
>
|
||||
<ArrowLeftOutlined />
|
||||
</Link>
|
||||
<FilePdfOutlined />
|
||||
<Text ellipsis={{ tooltip: documentInfo?.name }} style={{ width: 150 }}>
|
||||
{documentInfo?.name}
|
||||
</Text>
|
||||
</Space>
|
||||
<Space>
|
||||
<Segmented
|
||||
options={[
|
||||
{ label: t(ChunkTextMode.Full), value: ChunkTextMode.Full },
|
||||
{ label: t(ChunkTextMode.Ellipse), value: ChunkTextMode.Ellipse },
|
||||
]}
|
||||
onChange={changeChunkTextMode as SegmentedProps['onChange']}
|
||||
/>
|
||||
<Popover content={content} placement="bottom" arrow={false}>
|
||||
<Button>
|
||||
{t('bulk')}
|
||||
<DownOutlined />
|
||||
</Button>
|
||||
</Popover>
|
||||
{isShowSearchBox ? (
|
||||
<Input
|
||||
size="middle"
|
||||
placeholder={t('search')}
|
||||
prefix={<SearchOutlined />}
|
||||
allowClear
|
||||
onChange={handleInputChange}
|
||||
onBlur={handleSearchBlur}
|
||||
value={searchString}
|
||||
/>
|
||||
) : (
|
||||
<Button icon={<SearchOutlined />} onClick={handleSearchIconClick} />
|
||||
)}
|
||||
|
||||
<Popover content={filterContent} placement="bottom" arrow={false}>
|
||||
<Button icon={<FilterIcon />} />
|
||||
</Popover>
|
||||
<Button
|
||||
icon={<PlusOutlined />}
|
||||
type="primary"
|
||||
onClick={() => createChunk()}
|
||||
/>
|
||||
</Space>
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
export default ChunkToolBar;
|
||||
|
|
@ -1,55 +0,0 @@
|
|||
import { useGetKnowledgeSearchParams } from '@/hooks/route-hook';
|
||||
import { api_host } from '@/utils/api';
|
||||
import { useSize } from 'ahooks';
|
||||
import { CustomTextRenderer } from 'node_modules/react-pdf/dist/esm/shared/types';
|
||||
import { useCallback, useEffect, useMemo, useState } from 'react';
|
||||
|
||||
export const useDocumentResizeObserver = () => {
|
||||
const [containerWidth, setContainerWidth] = useState<number>();
|
||||
const [containerRef, setContainerRef] = useState<HTMLElement | null>(null);
|
||||
const size = useSize(containerRef);
|
||||
|
||||
const onResize = useCallback((width?: number) => {
|
||||
if (width) {
|
||||
setContainerWidth(width);
|
||||
}
|
||||
}, []);
|
||||
|
||||
useEffect(() => {
|
||||
onResize(size?.width);
|
||||
}, [size?.width, onResize]);
|
||||
|
||||
return { containerWidth, setContainerRef };
|
||||
};
|
||||
|
||||
function highlightPattern(text: string, pattern: string, pageNumber: number) {
|
||||
if (pageNumber === 2) {
|
||||
return `<mark>${text}</mark>`;
|
||||
}
|
||||
if (text.trim() !== '' && pattern.match(text)) {
|
||||
// return pattern.replace(text, (value) => `<mark>${value}</mark>`);
|
||||
return `<mark>${text}</mark>`;
|
||||
}
|
||||
return text.replace(pattern, (value) => `<mark>${value}</mark>`);
|
||||
}
|
||||
|
||||
export const useHighlightText = (searchText: string = '') => {
|
||||
const textRenderer: CustomTextRenderer = useCallback(
|
||||
(textItem) => {
|
||||
return highlightPattern(textItem.str, searchText, textItem.pageNumber);
|
||||
},
|
||||
[searchText],
|
||||
);
|
||||
|
||||
return textRenderer;
|
||||
};
|
||||
|
||||
export const useGetDocumentUrl = () => {
|
||||
const { documentId } = useGetKnowledgeSearchParams();
|
||||
|
||||
const url = useMemo(() => {
|
||||
return `${api_host}/document/get/${documentId}`;
|
||||
}, [documentId]);
|
||||
|
||||
return url;
|
||||
};
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
.documentContainer {
|
||||
width: 100%;
|
||||
height: calc(100vh - 284px);
|
||||
position: relative;
|
||||
:global(.PdfHighlighter) {
|
||||
overflow-x: hidden;
|
||||
}
|
||||
:global(.Highlight--scrolledTo .Highlight__part) {
|
||||
overflow-x: hidden;
|
||||
background-color: rgba(255, 226, 143, 1);
|
||||
}
|
||||
}
|
||||
|
|
@ -1,121 +0,0 @@
|
|||
import { Skeleton } from 'antd';
|
||||
import { memo, useEffect, useRef } from 'react';
|
||||
import {
|
||||
AreaHighlight,
|
||||
Highlight,
|
||||
IHighlight,
|
||||
PdfHighlighter,
|
||||
PdfLoader,
|
||||
Popup,
|
||||
} from 'react-pdf-highlighter';
|
||||
import { useGetDocumentUrl } from './hooks';
|
||||
|
||||
import { useCatchDocumentError } from '@/components/pdf-previewer/hooks';
|
||||
import FileError from '@/pages/document-viewer/file-error';
|
||||
import styles from './index.less';
|
||||
|
||||
interface IProps {
|
||||
highlights: IHighlight[];
|
||||
setWidthAndHeight: (width: number, height: number) => void;
|
||||
}
|
||||
const HighlightPopup = ({
|
||||
comment,
|
||||
}: {
|
||||
comment: { text: string; emoji: string };
|
||||
}) =>
|
||||
comment.text ? (
|
||||
<div className="Highlight__popup">
|
||||
{comment.emoji} {comment.text}
|
||||
</div>
|
||||
) : null;
|
||||
|
||||
// TODO: merge with DocumentPreviewer
|
||||
const Preview = ({ highlights: state, setWidthAndHeight }: IProps) => {
|
||||
const url = useGetDocumentUrl();
|
||||
|
||||
const ref = useRef<(highlight: IHighlight) => void>(() => {});
|
||||
const error = useCatchDocumentError(url);
|
||||
|
||||
const resetHash = () => {};
|
||||
|
||||
useEffect(() => {
|
||||
if (state.length > 0) {
|
||||
ref?.current(state[0]);
|
||||
}
|
||||
}, [state]);
|
||||
|
||||
return (
|
||||
<div className={styles.documentContainer}>
|
||||
<PdfLoader
|
||||
url={url}
|
||||
beforeLoad={<Skeleton active />}
|
||||
workerSrc="/pdfjs-dist/pdf.worker.min.js"
|
||||
errorMessage={<FileError>{error}</FileError>}
|
||||
>
|
||||
{(pdfDocument) => {
|
||||
pdfDocument.getPage(1).then((page) => {
|
||||
const viewport = page.getViewport({ scale: 1 });
|
||||
const width = viewport.width;
|
||||
const height = viewport.height;
|
||||
setWidthAndHeight(width, height);
|
||||
});
|
||||
|
||||
return (
|
||||
<PdfHighlighter
|
||||
pdfDocument={pdfDocument}
|
||||
enableAreaSelection={(event) => event.altKey}
|
||||
onScrollChange={resetHash}
|
||||
scrollRef={(scrollTo) => {
|
||||
ref.current = scrollTo;
|
||||
}}
|
||||
onSelectionFinished={() => null}
|
||||
highlightTransform={(
|
||||
highlight,
|
||||
index,
|
||||
setTip,
|
||||
hideTip,
|
||||
viewportToScaled,
|
||||
screenshot,
|
||||
isScrolledTo,
|
||||
) => {
|
||||
const isTextHighlight = !Boolean(
|
||||
highlight.content && highlight.content.image,
|
||||
);
|
||||
|
||||
const component = isTextHighlight ? (
|
||||
<Highlight
|
||||
isScrolledTo={isScrolledTo}
|
||||
position={highlight.position}
|
||||
comment={highlight.comment}
|
||||
/>
|
||||
) : (
|
||||
<AreaHighlight
|
||||
isScrolledTo={isScrolledTo}
|
||||
highlight={highlight}
|
||||
onChange={() => {}}
|
||||
/>
|
||||
);
|
||||
|
||||
return (
|
||||
<Popup
|
||||
popupContent={<HighlightPopup {...highlight} />}
|
||||
onMouseOver={(popupContent) =>
|
||||
setTip(highlight, () => popupContent)
|
||||
}
|
||||
onMouseOut={hideTip}
|
||||
key={index}
|
||||
>
|
||||
{component}
|
||||
</Popup>
|
||||
);
|
||||
}}
|
||||
highlights={state}
|
||||
/>
|
||||
);
|
||||
}}
|
||||
</PdfLoader>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(Preview);
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
export enum ChunkTextMode {
|
||||
Full = 'full',
|
||||
Ellipse = 'ellipse',
|
||||
}
|
||||
|
|
@ -1,129 +0,0 @@
|
|||
import {
|
||||
useCreateChunk,
|
||||
useDeleteChunk,
|
||||
useSelectChunkList,
|
||||
} from '@/hooks/chunk-hooks';
|
||||
import { useSetModalState, useShowDeleteConfirm } from '@/hooks/common-hooks';
|
||||
import { useGetKnowledgeSearchParams } from '@/hooks/route-hook';
|
||||
import { IChunk } from '@/interfaces/database/knowledge';
|
||||
import { buildChunkHighlights } from '@/utils/document-util';
|
||||
import { useCallback, useMemo, useState } from 'react';
|
||||
import { IHighlight } from 'react-pdf-highlighter';
|
||||
import { ChunkTextMode } from './constant';
|
||||
|
||||
export const useHandleChunkCardClick = () => {
|
||||
const [selectedChunkId, setSelectedChunkId] = useState<string>('');
|
||||
|
||||
const handleChunkCardClick = useCallback((chunkId: string) => {
|
||||
setSelectedChunkId(chunkId);
|
||||
}, []);
|
||||
|
||||
return { handleChunkCardClick, selectedChunkId };
|
||||
};
|
||||
|
||||
export const useGetSelectedChunk = (selectedChunkId: string) => {
|
||||
const data = useSelectChunkList();
|
||||
return (
|
||||
data?.data?.find((x) => x.chunk_id === selectedChunkId) ?? ({} as IChunk)
|
||||
);
|
||||
};
|
||||
|
||||
export const useGetChunkHighlights = (selectedChunkId: string) => {
|
||||
const [size, setSize] = useState({ width: 849, height: 1200 });
|
||||
const selectedChunk: IChunk = useGetSelectedChunk(selectedChunkId);
|
||||
|
||||
const highlights: IHighlight[] = useMemo(() => {
|
||||
return buildChunkHighlights(selectedChunk, size);
|
||||
}, [selectedChunk, size]);
|
||||
|
||||
const setWidthAndHeight = useCallback((width: number, height: number) => {
|
||||
setSize((pre) => {
|
||||
if (pre.height !== height || pre.width !== width) {
|
||||
return { height, width };
|
||||
}
|
||||
return pre;
|
||||
});
|
||||
}, []);
|
||||
|
||||
return { highlights, setWidthAndHeight };
|
||||
};
|
||||
|
||||
// Switch chunk text to be fully displayed or ellipse
|
||||
export const useChangeChunkTextMode = () => {
|
||||
const [textMode, setTextMode] = useState<ChunkTextMode>(ChunkTextMode.Full);
|
||||
|
||||
const changeChunkTextMode = useCallback((mode: ChunkTextMode) => {
|
||||
setTextMode(mode);
|
||||
}, []);
|
||||
|
||||
return { textMode, changeChunkTextMode };
|
||||
};
|
||||
|
||||
export const useDeleteChunkByIds = (): {
|
||||
removeChunk: (chunkIds: string[], documentId: string) => Promise<number>;
|
||||
} => {
|
||||
const { deleteChunk } = useDeleteChunk();
|
||||
const showDeleteConfirm = useShowDeleteConfirm();
|
||||
|
||||
const removeChunk = useCallback(
|
||||
(chunkIds: string[], documentId: string) => () => {
|
||||
return deleteChunk({ chunkIds, doc_id: documentId });
|
||||
},
|
||||
[deleteChunk],
|
||||
);
|
||||
|
||||
const onRemoveChunk = useCallback(
|
||||
(chunkIds: string[], documentId: string): Promise<number> => {
|
||||
return showDeleteConfirm({ onOk: removeChunk(chunkIds, documentId) });
|
||||
},
|
||||
[removeChunk, showDeleteConfirm],
|
||||
);
|
||||
|
||||
return {
|
||||
removeChunk: onRemoveChunk,
|
||||
};
|
||||
};
|
||||
|
||||
export const useUpdateChunk = () => {
|
||||
const [chunkId, setChunkId] = useState<string | undefined>('');
|
||||
const {
|
||||
visible: chunkUpdatingVisible,
|
||||
hideModal: hideChunkUpdatingModal,
|
||||
showModal,
|
||||
} = useSetModalState();
|
||||
const { createChunk, loading } = useCreateChunk();
|
||||
const { documentId } = useGetKnowledgeSearchParams();
|
||||
|
||||
const onChunkUpdatingOk = useCallback(
|
||||
async (params: IChunk) => {
|
||||
const code = await createChunk({
|
||||
...params,
|
||||
doc_id: documentId,
|
||||
chunk_id: chunkId,
|
||||
});
|
||||
|
||||
if (code === 0) {
|
||||
hideChunkUpdatingModal();
|
||||
}
|
||||
},
|
||||
[createChunk, hideChunkUpdatingModal, chunkId, documentId],
|
||||
);
|
||||
|
||||
const handleShowChunkUpdatingModal = useCallback(
|
||||
async (id?: string) => {
|
||||
setChunkId(id);
|
||||
showModal();
|
||||
},
|
||||
[showModal],
|
||||
);
|
||||
|
||||
return {
|
||||
chunkUpdatingLoading: loading,
|
||||
onChunkUpdatingOk,
|
||||
chunkUpdatingVisible,
|
||||
hideChunkUpdatingModal,
|
||||
showChunkUpdatingModal: handleShowChunkUpdatingModal,
|
||||
chunkId,
|
||||
documentId,
|
||||
};
|
||||
};
|
||||
|
|
@ -1,92 +0,0 @@
|
|||
.chunkPage {
|
||||
padding: 24px;
|
||||
|
||||
display: flex;
|
||||
// height: calc(100vh - 112px);
|
||||
flex-direction: column;
|
||||
|
||||
.filter {
|
||||
margin: 10px 0;
|
||||
display: flex;
|
||||
height: 32px;
|
||||
justify-content: space-between;
|
||||
}
|
||||
|
||||
.pagePdfWrapper {
|
||||
width: 60%;
|
||||
}
|
||||
|
||||
.pageWrapper {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.pageContent {
|
||||
flex: 1;
|
||||
width: 100%;
|
||||
padding-right: 12px;
|
||||
overflow-y: auto;
|
||||
|
||||
.spin {
|
||||
min-height: 400px;
|
||||
}
|
||||
}
|
||||
|
||||
.documentPreview {
|
||||
width: 40%;
|
||||
height: 100%;
|
||||
}
|
||||
|
||||
.chunkContainer {
|
||||
display: flex;
|
||||
height: calc(100vh - 332px);
|
||||
}
|
||||
|
||||
.chunkOtherContainer {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.pageFooter {
|
||||
padding-top: 10px;
|
||||
height: 32px;
|
||||
}
|
||||
}
|
||||
|
||||
.container {
|
||||
height: 100px;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
justify-content: space-between;
|
||||
|
||||
.content {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
|
||||
.context {
|
||||
flex: 1;
|
||||
// width: 207px;
|
||||
height: 88px;
|
||||
overflow: hidden;
|
||||
}
|
||||
}
|
||||
|
||||
.footer {
|
||||
height: 20px;
|
||||
|
||||
.text {
|
||||
margin-left: 10px;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.card {
|
||||
:global {
|
||||
.ant-card-body {
|
||||
padding: 10px;
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
margin-bottom: 10px;
|
||||
}
|
||||
|
||||
cursor: pointer;
|
||||
}
|
||||
|
|
@ -1,202 +0,0 @@
|
|||
import { useFetchNextChunkList, useSwitchChunk } from '@/hooks/chunk-hooks';
|
||||
import type { PaginationProps } from 'antd';
|
||||
import { Divider, Flex, Pagination, Space, Spin, message } from 'antd';
|
||||
import classNames from 'classnames';
|
||||
import { useCallback, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import ChunkCard from './components/chunk-card';
|
||||
import CreatingModal from './components/chunk-creating-modal';
|
||||
import ChunkToolBar from './components/chunk-toolbar';
|
||||
import DocumentPreview from './components/document-preview/preview';
|
||||
import {
|
||||
useChangeChunkTextMode,
|
||||
useDeleteChunkByIds,
|
||||
useGetChunkHighlights,
|
||||
useHandleChunkCardClick,
|
||||
useUpdateChunk,
|
||||
} from './hooks';
|
||||
|
||||
import styles from './index.less';
|
||||
|
||||
const Chunk = () => {
|
||||
const [selectedChunkIds, setSelectedChunkIds] = useState<string[]>([]);
|
||||
const { removeChunk } = useDeleteChunkByIds();
|
||||
const {
|
||||
data: { documentInfo, data = [], total },
|
||||
pagination,
|
||||
loading,
|
||||
searchString,
|
||||
handleInputChange,
|
||||
available,
|
||||
handleSetAvailable,
|
||||
} = useFetchNextChunkList();
|
||||
const { handleChunkCardClick, selectedChunkId } = useHandleChunkCardClick();
|
||||
const isPdf = documentInfo?.type === 'pdf';
|
||||
|
||||
const { t } = useTranslation();
|
||||
const { changeChunkTextMode, textMode } = useChangeChunkTextMode();
|
||||
const { switchChunk } = useSwitchChunk();
|
||||
const {
|
||||
chunkUpdatingLoading,
|
||||
onChunkUpdatingOk,
|
||||
showChunkUpdatingModal,
|
||||
hideChunkUpdatingModal,
|
||||
chunkId,
|
||||
chunkUpdatingVisible,
|
||||
documentId,
|
||||
} = useUpdateChunk();
|
||||
|
||||
const onPaginationChange: PaginationProps['onShowSizeChange'] = (
|
||||
page,
|
||||
size,
|
||||
) => {
|
||||
setSelectedChunkIds([]);
|
||||
pagination.onChange?.(page, size);
|
||||
};
|
||||
|
||||
const selectAllChunk = useCallback(
|
||||
(checked: boolean) => {
|
||||
setSelectedChunkIds(checked ? data.map((x) => x.chunk_id) : []);
|
||||
},
|
||||
[data],
|
||||
);
|
||||
|
||||
const handleSingleCheckboxClick = useCallback(
|
||||
(chunkId: string, checked: boolean) => {
|
||||
setSelectedChunkIds((previousIds) => {
|
||||
const idx = previousIds.findIndex((x) => x === chunkId);
|
||||
const nextIds = [...previousIds];
|
||||
if (checked && idx === -1) {
|
||||
nextIds.push(chunkId);
|
||||
} else if (!checked && idx !== -1) {
|
||||
nextIds.splice(idx, 1);
|
||||
}
|
||||
return nextIds;
|
||||
});
|
||||
},
|
||||
[],
|
||||
);
|
||||
|
||||
const showSelectedChunkWarning = useCallback(() => {
|
||||
message.warning(t('message.pleaseSelectChunk'));
|
||||
}, [t]);
|
||||
|
||||
const handleRemoveChunk = useCallback(async () => {
|
||||
if (selectedChunkIds.length > 0) {
|
||||
const resCode: number = await removeChunk(selectedChunkIds, documentId);
|
||||
if (resCode === 0) {
|
||||
setSelectedChunkIds([]);
|
||||
}
|
||||
} else {
|
||||
showSelectedChunkWarning();
|
||||
}
|
||||
}, [selectedChunkIds, documentId, removeChunk, showSelectedChunkWarning]);
|
||||
|
||||
const handleSwitchChunk = useCallback(
|
||||
async (available?: number, chunkIds?: string[]) => {
|
||||
let ids = chunkIds;
|
||||
if (!chunkIds) {
|
||||
ids = selectedChunkIds;
|
||||
if (selectedChunkIds.length === 0) {
|
||||
showSelectedChunkWarning();
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
const resCode: number = await switchChunk({
|
||||
chunk_ids: ids,
|
||||
available_int: available,
|
||||
doc_id: documentId,
|
||||
});
|
||||
if (!chunkIds && resCode === 0) {
|
||||
}
|
||||
},
|
||||
[switchChunk, documentId, selectedChunkIds, showSelectedChunkWarning],
|
||||
);
|
||||
|
||||
const { highlights, setWidthAndHeight } =
|
||||
useGetChunkHighlights(selectedChunkId);
|
||||
|
||||
return (
|
||||
<>
|
||||
<div className={styles.chunkPage}>
|
||||
<ChunkToolBar
|
||||
selectAllChunk={selectAllChunk}
|
||||
createChunk={showChunkUpdatingModal}
|
||||
removeChunk={handleRemoveChunk}
|
||||
checked={selectedChunkIds.length === data.length}
|
||||
switchChunk={handleSwitchChunk}
|
||||
changeChunkTextMode={changeChunkTextMode}
|
||||
searchString={searchString}
|
||||
handleInputChange={handleInputChange}
|
||||
available={available}
|
||||
handleSetAvailable={handleSetAvailable}
|
||||
></ChunkToolBar>
|
||||
<Divider></Divider>
|
||||
<Flex flex={1} gap={'middle'}>
|
||||
<Flex
|
||||
vertical
|
||||
className={isPdf ? styles.pagePdfWrapper : styles.pageWrapper}
|
||||
>
|
||||
<Spin spinning={loading} className={styles.spin} size="large">
|
||||
<div className={styles.pageContent}>
|
||||
<Space
|
||||
direction="vertical"
|
||||
size={'middle'}
|
||||
className={classNames(styles.chunkContainer, {
|
||||
[styles.chunkOtherContainer]: !isPdf,
|
||||
})}
|
||||
>
|
||||
{data.map((item) => (
|
||||
<ChunkCard
|
||||
item={item}
|
||||
key={item.chunk_id}
|
||||
editChunk={showChunkUpdatingModal}
|
||||
checked={selectedChunkIds.some(
|
||||
(x) => x === item.chunk_id,
|
||||
)}
|
||||
handleCheckboxClick={handleSingleCheckboxClick}
|
||||
switchChunk={handleSwitchChunk}
|
||||
clickChunkCard={handleChunkCardClick}
|
||||
selected={item.chunk_id === selectedChunkId}
|
||||
textMode={textMode}
|
||||
></ChunkCard>
|
||||
))}
|
||||
</Space>
|
||||
</div>
|
||||
</Spin>
|
||||
<div className={styles.pageFooter}>
|
||||
<Pagination
|
||||
{...pagination}
|
||||
total={total}
|
||||
size={'small'}
|
||||
onChange={onPaginationChange}
|
||||
/>
|
||||
</div>
|
||||
</Flex>
|
||||
{isPdf && (
|
||||
<section className={styles.documentPreview}>
|
||||
<DocumentPreview
|
||||
highlights={highlights}
|
||||
setWidthAndHeight={setWidthAndHeight}
|
||||
></DocumentPreview>
|
||||
</section>
|
||||
)}
|
||||
</Flex>
|
||||
</div>
|
||||
{chunkUpdatingVisible && (
|
||||
<CreatingModal
|
||||
doc_id={documentId}
|
||||
chunkId={chunkId}
|
||||
hideModal={hideChunkUpdatingModal}
|
||||
visible={chunkUpdatingVisible}
|
||||
loading={chunkUpdatingLoading}
|
||||
onOk={onChunkUpdatingOk}
|
||||
parserId={documentInfo.parser_id}
|
||||
/>
|
||||
)}
|
||||
</>
|
||||
);
|
||||
};
|
||||
|
||||
export default Chunk;
|
||||
|
|
@ -1,24 +0,0 @@
|
|||
export type FormListItem = {
|
||||
frequency: number;
|
||||
tag: string;
|
||||
};
|
||||
|
||||
export function transformTagFeaturesArrayToObject(
|
||||
list: Array<FormListItem> = [],
|
||||
) {
|
||||
return list.reduce<Record<string, number>>((pre, cur) => {
|
||||
pre[cur.tag] = cur.frequency;
|
||||
|
||||
return pre;
|
||||
}, {});
|
||||
}
|
||||
|
||||
export function transformTagFeaturesObjectToArray(
|
||||
object: Record<string, number> = {},
|
||||
) {
|
||||
return Object.keys(object).reduce<Array<FormListItem>>((pre, key) => {
|
||||
pre.push({ frequency: object[key], tag: key });
|
||||
|
||||
return pre;
|
||||
}, []);
|
||||
}
|
||||
|
|
@ -1,7 +0,0 @@
|
|||
import { Outlet } from 'umi';
|
||||
|
||||
export const KnowledgeDataset = () => {
|
||||
return <Outlet></Outlet>;
|
||||
};
|
||||
|
||||
export default KnowledgeDataset;
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
import { RunningStatus } from '@/constants/knowledge';
|
||||
|
||||
export const RunningStatusMap = {
|
||||
[RunningStatus.UNSTART]: {
|
||||
label: 'UNSTART',
|
||||
color: 'cyan',
|
||||
},
|
||||
[RunningStatus.RUNNING]: {
|
||||
label: 'Parsing',
|
||||
color: 'blue',
|
||||
},
|
||||
[RunningStatus.CANCEL]: { label: 'CANCEL', color: 'orange' },
|
||||
[RunningStatus.DONE]: { label: 'SUCCESS', color: 'geekblue' },
|
||||
[RunningStatus.FAIL]: { label: 'FAIL', color: 'red' },
|
||||
};
|
||||
|
||||
export * from '@/constants/knowledge';
|
||||
|
|
@ -1,49 +0,0 @@
|
|||
import { IModalManagerChildrenProps } from '@/components/modal-manager';
|
||||
import { Form, Input, Modal } from 'antd';
|
||||
import React from 'react';
|
||||
|
||||
type FieldType = {
|
||||
name?: string;
|
||||
};
|
||||
|
||||
interface IProps extends Omit<IModalManagerChildrenProps, 'showModal'> {
|
||||
loading: boolean;
|
||||
onOk: (name: string) => void;
|
||||
showModal?(): void;
|
||||
}
|
||||
|
||||
const FileCreatingModal: React.FC<IProps> = ({ visible, hideModal, onOk }) => {
|
||||
const [form] = Form.useForm();
|
||||
|
||||
const handleOk = async () => {
|
||||
const values = await form.validateFields();
|
||||
onOk(values.name);
|
||||
};
|
||||
|
||||
return (
|
||||
<Modal
|
||||
title="File Name"
|
||||
open={visible}
|
||||
onOk={handleOk}
|
||||
onCancel={hideModal}
|
||||
>
|
||||
<Form
|
||||
form={form}
|
||||
name="validateOnly"
|
||||
labelCol={{ span: 4 }}
|
||||
wrapperCol={{ span: 20 }}
|
||||
style={{ maxWidth: 600 }}
|
||||
autoComplete="off"
|
||||
>
|
||||
<Form.Item<FieldType>
|
||||
label="File Name"
|
||||
name="name"
|
||||
rules={[{ required: true, message: 'Please input name!' }]}
|
||||
>
|
||||
<Input />
|
||||
</Form.Item>
|
||||
</Form>
|
||||
</Modal>
|
||||
);
|
||||
};
|
||||
export default FileCreatingModal;
|
||||
|
|
@ -1,240 +0,0 @@
|
|||
import { ReactComponent as CancelIcon } from '@/assets/svg/cancel.svg';
|
||||
import { ReactComponent as DeleteIcon } from '@/assets/svg/delete.svg';
|
||||
import { ReactComponent as DisableIcon } from '@/assets/svg/disable.svg';
|
||||
import { ReactComponent as EnableIcon } from '@/assets/svg/enable.svg';
|
||||
import { ReactComponent as RunIcon } from '@/assets/svg/run.svg';
|
||||
import { useShowDeleteConfirm, useTranslate } from '@/hooks/common-hooks';
|
||||
import {
|
||||
useRemoveNextDocument,
|
||||
useRunNextDocument,
|
||||
useSetNextDocumentStatus,
|
||||
} from '@/hooks/document-hooks';
|
||||
import { IDocumentInfo } from '@/interfaces/database/document';
|
||||
import {
|
||||
DownOutlined,
|
||||
FileOutlined,
|
||||
FileTextOutlined,
|
||||
PlusOutlined,
|
||||
SearchOutlined,
|
||||
} from '@ant-design/icons';
|
||||
import { Button, Dropdown, Flex, Input, MenuProps, Space } from 'antd';
|
||||
import { useCallback, useMemo } from 'react';
|
||||
import { toast } from 'sonner';
|
||||
import { RunningStatus } from './constant';
|
||||
|
||||
import styles from './index.less';
|
||||
|
||||
interface IProps {
|
||||
selectedRowKeys: string[];
|
||||
showCreateModal(): void;
|
||||
showWebCrawlModal(): void;
|
||||
showDocumentUploadModal(): void;
|
||||
searchString: string;
|
||||
handleInputChange: React.ChangeEventHandler<HTMLInputElement>;
|
||||
documents: IDocumentInfo[];
|
||||
}
|
||||
|
||||
const DocumentToolbar = ({
|
||||
searchString,
|
||||
selectedRowKeys,
|
||||
showCreateModal,
|
||||
showDocumentUploadModal,
|
||||
handleInputChange,
|
||||
documents,
|
||||
}: IProps) => {
|
||||
const { t } = useTranslate('knowledgeDetails');
|
||||
const { removeDocument } = useRemoveNextDocument();
|
||||
const showDeleteConfirm = useShowDeleteConfirm();
|
||||
const { runDocumentByIds } = useRunNextDocument();
|
||||
const { setDocumentStatus } = useSetNextDocumentStatus();
|
||||
|
||||
const actionItems: MenuProps['items'] = useMemo(() => {
|
||||
return [
|
||||
{
|
||||
key: '1',
|
||||
onClick: showDocumentUploadModal,
|
||||
label: (
|
||||
<div>
|
||||
<Button type="link">
|
||||
<Space>
|
||||
<FileTextOutlined />
|
||||
{t('localFiles')}
|
||||
</Space>
|
||||
</Button>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '3',
|
||||
onClick: showCreateModal,
|
||||
label: (
|
||||
<div>
|
||||
<Button type="link">
|
||||
<FileOutlined />
|
||||
{t('emptyFiles')}
|
||||
</Button>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
];
|
||||
}, [showDocumentUploadModal, showCreateModal, t]);
|
||||
|
||||
const handleDelete = useCallback(() => {
|
||||
const deletedKeys = selectedRowKeys.filter(
|
||||
(x) =>
|
||||
!documents
|
||||
.filter((y) => y.run === RunningStatus.RUNNING)
|
||||
.some((y) => y.id === x),
|
||||
);
|
||||
if (deletedKeys.length === 0) {
|
||||
toast.error(t('theDocumentBeingParsedCannotBeDeleted'));
|
||||
return;
|
||||
}
|
||||
showDeleteConfirm({
|
||||
onOk: () => {
|
||||
removeDocument(deletedKeys);
|
||||
},
|
||||
});
|
||||
}, [selectedRowKeys, showDeleteConfirm, documents, t, removeDocument]);
|
||||
|
||||
const runDocument = useCallback(
|
||||
(run: number) => {
|
||||
runDocumentByIds({
|
||||
documentIds: selectedRowKeys,
|
||||
run,
|
||||
shouldDelete: false,
|
||||
});
|
||||
},
|
||||
[runDocumentByIds, selectedRowKeys],
|
||||
);
|
||||
|
||||
const handleRunClick = useCallback(() => {
|
||||
runDocument(1);
|
||||
}, [runDocument]);
|
||||
|
||||
const handleCancelClick = useCallback(() => {
|
||||
runDocument(2);
|
||||
}, [runDocument]);
|
||||
|
||||
const onChangeStatus = useCallback(
|
||||
(enabled: boolean) => {
|
||||
selectedRowKeys.forEach((id) => {
|
||||
setDocumentStatus({ status: enabled, documentId: id });
|
||||
});
|
||||
},
|
||||
[selectedRowKeys, setDocumentStatus],
|
||||
);
|
||||
|
||||
const handleEnableClick = useCallback(() => {
|
||||
onChangeStatus(true);
|
||||
}, [onChangeStatus]);
|
||||
|
||||
const handleDisableClick = useCallback(() => {
|
||||
onChangeStatus(false);
|
||||
}, [onChangeStatus]);
|
||||
|
||||
const disabled = selectedRowKeys.length === 0;
|
||||
|
||||
const items: MenuProps['items'] = useMemo(() => {
|
||||
return [
|
||||
{
|
||||
key: '0',
|
||||
onClick: handleEnableClick,
|
||||
label: (
|
||||
<Flex gap={10}>
|
||||
<EnableIcon></EnableIcon>
|
||||
<b>{t('enabled')}</b>
|
||||
</Flex>
|
||||
),
|
||||
},
|
||||
{
|
||||
key: '1',
|
||||
onClick: handleDisableClick,
|
||||
label: (
|
||||
<Flex gap={10}>
|
||||
<DisableIcon></DisableIcon>
|
||||
<b>{t('disabled')}</b>
|
||||
</Flex>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '2',
|
||||
onClick: handleRunClick,
|
||||
label: (
|
||||
<Flex gap={10}>
|
||||
<RunIcon></RunIcon>
|
||||
<b>{t('run')}</b>
|
||||
</Flex>
|
||||
),
|
||||
},
|
||||
{
|
||||
key: '3',
|
||||
onClick: handleCancelClick,
|
||||
label: (
|
||||
<Flex gap={10}>
|
||||
<CancelIcon />
|
||||
<b>{t('cancel')}</b>
|
||||
</Flex>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '4',
|
||||
onClick: handleDelete,
|
||||
label: (
|
||||
<Flex gap={10}>
|
||||
<span className={styles.deleteIconWrapper}>
|
||||
<DeleteIcon width={18} />
|
||||
</span>
|
||||
<b>{t('delete', { keyPrefix: 'common' })}</b>
|
||||
</Flex>
|
||||
),
|
||||
},
|
||||
];
|
||||
}, [
|
||||
handleDelete,
|
||||
handleRunClick,
|
||||
handleCancelClick,
|
||||
t,
|
||||
handleDisableClick,
|
||||
handleEnableClick,
|
||||
]);
|
||||
|
||||
return (
|
||||
<div className={styles.filter}>
|
||||
<Dropdown
|
||||
menu={{ items }}
|
||||
placement="bottom"
|
||||
arrow={false}
|
||||
disabled={disabled}
|
||||
>
|
||||
<Button>
|
||||
<Space>
|
||||
<b> {t('bulk')}</b>
|
||||
<DownOutlined />
|
||||
</Space>
|
||||
</Button>
|
||||
</Dropdown>
|
||||
<Space>
|
||||
<Input
|
||||
placeholder={t('searchFiles')}
|
||||
value={searchString}
|
||||
style={{ width: 220 }}
|
||||
allowClear
|
||||
onChange={handleInputChange}
|
||||
prefix={<SearchOutlined />}
|
||||
/>
|
||||
|
||||
<Dropdown menu={{ items: actionItems }} trigger={['click']}>
|
||||
<Button type="primary" icon={<PlusOutlined />}>
|
||||
{t('addFile')}
|
||||
</Button>
|
||||
</Dropdown>
|
||||
</Space>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default DocumentToolbar;
|
||||
|
|
@ -1,364 +0,0 @@
|
|||
import { useSetModalState } from '@/hooks/common-hooks';
|
||||
import {
|
||||
useCreateNextDocument,
|
||||
useNextWebCrawl,
|
||||
useRunNextDocument,
|
||||
useSaveNextDocumentName,
|
||||
useSetDocumentMeta,
|
||||
useSetNextDocumentParser,
|
||||
useUploadNextDocument,
|
||||
} from '@/hooks/document-hooks';
|
||||
import { useGetKnowledgeSearchParams } from '@/hooks/route-hook';
|
||||
import { IDocumentInfo } from '@/interfaces/database/document';
|
||||
import { IChangeParserConfigRequestBody } from '@/interfaces/request/document';
|
||||
import { UploadFile } from 'antd';
|
||||
import { TableRowSelection } from 'antd/es/table/interface';
|
||||
import { useCallback, useState } from 'react';
|
||||
import { useNavigate } from 'umi';
|
||||
import { KnowledgeRouteKey } from './constant';
|
||||
|
||||
export const useNavigateToOtherPage = () => {
|
||||
const navigate = useNavigate();
|
||||
const { knowledgeId } = useGetKnowledgeSearchParams();
|
||||
|
||||
const linkToUploadPage = useCallback(() => {
|
||||
navigate(`/knowledge/dataset/upload?id=${knowledgeId}`);
|
||||
}, [navigate, knowledgeId]);
|
||||
|
||||
const toChunk = useCallback(
|
||||
(id: string) => {
|
||||
navigate(
|
||||
`/knowledge/${KnowledgeRouteKey.Dataset}/chunk?id=${knowledgeId}&doc_id=${id}`,
|
||||
);
|
||||
},
|
||||
[navigate, knowledgeId],
|
||||
);
|
||||
|
||||
return { linkToUploadPage, toChunk };
|
||||
};
|
||||
|
||||
export const useRenameDocument = (documentId: string) => {
|
||||
const { saveName, loading } = useSaveNextDocumentName();
|
||||
|
||||
const {
|
||||
visible: renameVisible,
|
||||
hideModal: hideRenameModal,
|
||||
showModal: showRenameModal,
|
||||
} = useSetModalState();
|
||||
|
||||
const onRenameOk = useCallback(
|
||||
async (name: string) => {
|
||||
const ret = await saveName({ documentId, name });
|
||||
if (ret === 0) {
|
||||
hideRenameModal();
|
||||
}
|
||||
},
|
||||
[hideRenameModal, saveName, documentId],
|
||||
);
|
||||
|
||||
return {
|
||||
renameLoading: loading,
|
||||
onRenameOk,
|
||||
renameVisible,
|
||||
hideRenameModal,
|
||||
showRenameModal,
|
||||
};
|
||||
};
|
||||
|
||||
export const useCreateEmptyDocument = () => {
|
||||
const { createDocument, loading } = useCreateNextDocument();
|
||||
|
||||
const {
|
||||
visible: createVisible,
|
||||
hideModal: hideCreateModal,
|
||||
showModal: showCreateModal,
|
||||
} = useSetModalState();
|
||||
|
||||
const onCreateOk = useCallback(
|
||||
async (name: string) => {
|
||||
const ret = await createDocument(name);
|
||||
if (ret === 0) {
|
||||
hideCreateModal();
|
||||
}
|
||||
},
|
||||
[hideCreateModal, createDocument],
|
||||
);
|
||||
|
||||
return {
|
||||
createLoading: loading,
|
||||
onCreateOk,
|
||||
createVisible,
|
||||
hideCreateModal,
|
||||
showCreateModal,
|
||||
};
|
||||
};
|
||||
|
||||
export const useChangeDocumentParser = (documentId: string) => {
|
||||
const { setDocumentParser, loading } = useSetNextDocumentParser();
|
||||
|
||||
const {
|
||||
visible: changeParserVisible,
|
||||
hideModal: hideChangeParserModal,
|
||||
showModal: showChangeParserModal,
|
||||
} = useSetModalState();
|
||||
|
||||
const onChangeParserOk = useCallback(
|
||||
async (parserId: string, parserConfig: IChangeParserConfigRequestBody) => {
|
||||
const ret = await setDocumentParser({
|
||||
parserId,
|
||||
documentId,
|
||||
parserConfig,
|
||||
});
|
||||
if (ret === 0) {
|
||||
hideChangeParserModal();
|
||||
}
|
||||
},
|
||||
[hideChangeParserModal, setDocumentParser, documentId],
|
||||
);
|
||||
|
||||
return {
|
||||
changeParserLoading: loading,
|
||||
onChangeParserOk,
|
||||
changeParserVisible,
|
||||
hideChangeParserModal,
|
||||
showChangeParserModal,
|
||||
};
|
||||
};
|
||||
|
||||
export const useGetRowSelection = () => {
|
||||
const [selectedRowKeys, setSelectedRowKeys] = useState<React.Key[]>([]);
|
||||
|
||||
const rowSelection: TableRowSelection<IDocumentInfo> = {
|
||||
selectedRowKeys,
|
||||
onChange: (newSelectedRowKeys: React.Key[]) => {
|
||||
setSelectedRowKeys(newSelectedRowKeys);
|
||||
},
|
||||
};
|
||||
|
||||
return rowSelection;
|
||||
};
|
||||
|
||||
export const useHandleUploadDocument = () => {
|
||||
const {
|
||||
visible: documentUploadVisible,
|
||||
hideModal: hideDocumentUploadModal,
|
||||
showModal: showDocumentUploadModal,
|
||||
} = useSetModalState();
|
||||
const [fileList, setFileList] = useState<UploadFile[]>([]);
|
||||
const [uploadProgress, setUploadProgress] = useState<number>(0);
|
||||
const { uploadDocument, loading } = useUploadNextDocument();
|
||||
const { runDocumentByIds } = useRunNextDocument();
|
||||
|
||||
const onDocumentUploadOk = useCallback(
|
||||
async ({
|
||||
parseOnCreation,
|
||||
directoryFileList,
|
||||
}: {
|
||||
directoryFileList: UploadFile[];
|
||||
parseOnCreation: boolean;
|
||||
}): Promise<number | undefined> => {
|
||||
const processFileGroup = async (filesPart: UploadFile[]) => {
|
||||
// set status to uploading on files
|
||||
setFileList(
|
||||
fileList.map((file) => {
|
||||
if (!filesPart.includes(file)) {
|
||||
return file;
|
||||
}
|
||||
|
||||
let newFile = file;
|
||||
newFile.status = 'uploading';
|
||||
newFile.percent = 1;
|
||||
return newFile;
|
||||
}),
|
||||
);
|
||||
|
||||
const ret = await uploadDocument(filesPart);
|
||||
|
||||
const files = ret?.data || [];
|
||||
const successfulFilenames = files.map((file: any) => file.name);
|
||||
|
||||
// set status to done or error on files (based on response)
|
||||
setFileList(
|
||||
fileList.map((file) => {
|
||||
if (!filesPart.includes(file)) {
|
||||
return file;
|
||||
}
|
||||
|
||||
let newFile = file;
|
||||
newFile.status = successfulFilenames.includes(file.name)
|
||||
? 'done'
|
||||
: 'error';
|
||||
newFile.percent = 100;
|
||||
newFile.response = ret.message;
|
||||
return newFile;
|
||||
}),
|
||||
);
|
||||
|
||||
return {
|
||||
code: ret?.code,
|
||||
fileIds: files.map((file: any) => file.id),
|
||||
totalSuccess: successfulFilenames.length,
|
||||
};
|
||||
};
|
||||
const totalFiles = fileList.length;
|
||||
|
||||
if (directoryFileList.length > 0) {
|
||||
const ret = await uploadDocument(directoryFileList);
|
||||
if (ret?.code === 0) {
|
||||
hideDocumentUploadModal();
|
||||
}
|
||||
if (totalFiles === 0) {
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
if (totalFiles === 0) {
|
||||
console.log('No files to upload');
|
||||
hideDocumentUploadModal();
|
||||
return 0;
|
||||
}
|
||||
|
||||
let totalSuccess = 0;
|
||||
let codes = [];
|
||||
let toRunFileIds: any[] = [];
|
||||
for (let i = 0; i < totalFiles; i += 10) {
|
||||
setUploadProgress(Math.floor((i / totalFiles) * 100));
|
||||
const files = fileList.slice(i, i + 10);
|
||||
const {
|
||||
code,
|
||||
totalSuccess: count,
|
||||
fileIds,
|
||||
} = await processFileGroup(files);
|
||||
codes.push(code);
|
||||
totalSuccess += count;
|
||||
toRunFileIds = toRunFileIds.concat(fileIds);
|
||||
}
|
||||
|
||||
const allSuccess = codes.every((code) => code === 0);
|
||||
const any500 = codes.some((code) => code === 500);
|
||||
|
||||
let code = 500;
|
||||
if (allSuccess || (any500 && totalSuccess === totalFiles)) {
|
||||
code = 0;
|
||||
hideDocumentUploadModal();
|
||||
}
|
||||
|
||||
if (parseOnCreation) {
|
||||
await runDocumentByIds({
|
||||
documentIds: toRunFileIds,
|
||||
run: 1,
|
||||
shouldDelete: false,
|
||||
});
|
||||
}
|
||||
|
||||
setUploadProgress(100);
|
||||
|
||||
return code;
|
||||
},
|
||||
[fileList, uploadDocument, hideDocumentUploadModal, runDocumentByIds],
|
||||
);
|
||||
|
||||
return {
|
||||
documentUploadLoading: loading,
|
||||
onDocumentUploadOk,
|
||||
documentUploadVisible,
|
||||
hideDocumentUploadModal,
|
||||
showDocumentUploadModal,
|
||||
uploadFileList: fileList,
|
||||
setUploadFileList: setFileList,
|
||||
uploadProgress,
|
||||
setUploadProgress,
|
||||
};
|
||||
};
|
||||
|
||||
export const useHandleWebCrawl = () => {
|
||||
const {
|
||||
visible: webCrawlUploadVisible,
|
||||
hideModal: hideWebCrawlUploadModal,
|
||||
showModal: showWebCrawlUploadModal,
|
||||
} = useSetModalState();
|
||||
const { webCrawl, loading } = useNextWebCrawl();
|
||||
|
||||
const onWebCrawlUploadOk = useCallback(
|
||||
async (name: string, url: string) => {
|
||||
const ret = await webCrawl({ name, url });
|
||||
if (ret === 0) {
|
||||
hideWebCrawlUploadModal();
|
||||
return 0;
|
||||
}
|
||||
return -1;
|
||||
},
|
||||
[webCrawl, hideWebCrawlUploadModal],
|
||||
);
|
||||
|
||||
return {
|
||||
webCrawlUploadLoading: loading,
|
||||
onWebCrawlUploadOk,
|
||||
webCrawlUploadVisible,
|
||||
hideWebCrawlUploadModal,
|
||||
showWebCrawlUploadModal,
|
||||
};
|
||||
};
|
||||
|
||||
export const useHandleRunDocumentByIds = (id: string) => {
|
||||
const { runDocumentByIds, loading } = useRunNextDocument();
|
||||
const [currentId, setCurrentId] = useState<string>('');
|
||||
const isLoading = loading && currentId !== '' && currentId === id;
|
||||
|
||||
const handleRunDocumentByIds = async (
|
||||
documentId: string,
|
||||
isRunning: boolean,
|
||||
shouldDelete: boolean = false,
|
||||
) => {
|
||||
if (isLoading) {
|
||||
return;
|
||||
}
|
||||
setCurrentId(documentId);
|
||||
try {
|
||||
await runDocumentByIds({
|
||||
documentIds: [documentId],
|
||||
run: isRunning ? 2 : 1,
|
||||
shouldDelete,
|
||||
});
|
||||
setCurrentId('');
|
||||
} catch (error) {
|
||||
setCurrentId('');
|
||||
}
|
||||
};
|
||||
|
||||
return {
|
||||
handleRunDocumentByIds,
|
||||
loading: isLoading,
|
||||
};
|
||||
};
|
||||
|
||||
export const useShowMetaModal = (documentId: string) => {
|
||||
const { setDocumentMeta, loading } = useSetDocumentMeta();
|
||||
|
||||
const {
|
||||
visible: setMetaVisible,
|
||||
hideModal: hideSetMetaModal,
|
||||
showModal: showSetMetaModal,
|
||||
} = useSetModalState();
|
||||
|
||||
const onSetMetaModalOk = useCallback(
|
||||
async (meta: string) => {
|
||||
const ret = await setDocumentMeta({
|
||||
documentId,
|
||||
meta,
|
||||
});
|
||||
if (ret === 0) {
|
||||
hideSetMetaModal();
|
||||
}
|
||||
},
|
||||
[setDocumentMeta, documentId, hideSetMetaModal],
|
||||
);
|
||||
|
||||
return {
|
||||
setMetaLoading: loading,
|
||||
onSetMetaModalOk,
|
||||
setMetaVisible,
|
||||
hideSetMetaModal,
|
||||
showSetMetaModal,
|
||||
};
|
||||
};
|
||||
|
|
@ -1,54 +0,0 @@
|
|||
.datasetWrapper {
|
||||
padding: 30px 30px 0;
|
||||
height: 100%;
|
||||
}
|
||||
|
||||
.documentTable {
|
||||
tbody {
|
||||
// height: calc(100vh - 508px);
|
||||
}
|
||||
}
|
||||
|
||||
.filter {
|
||||
height: 32px;
|
||||
display: flex;
|
||||
margin: 10px 0;
|
||||
justify-content: space-between;
|
||||
padding: 24px 0;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
.deleteIconWrapper {
|
||||
width: 22px;
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
.img {
|
||||
height: 24px;
|
||||
width: 24px;
|
||||
display: inline-block;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
.column {
|
||||
min-width: 200px;
|
||||
}
|
||||
|
||||
.toChunks {
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
.pageInputNumber {
|
||||
width: 220px;
|
||||
}
|
||||
|
||||
.questionIcon {
|
||||
margin-inline-start: 4px;
|
||||
color: rgba(0, 0, 0, 0.45);
|
||||
cursor: help;
|
||||
writing-mode: horizontal-tb;
|
||||
}
|
||||
|
||||
.nameText {
|
||||
color: #1677ff;
|
||||
}
|
||||
|
|
@ -1,275 +0,0 @@
|
|||
import ChunkMethodModal from '@/components/chunk-method-modal';
|
||||
import SvgIcon from '@/components/svg-icon';
|
||||
import {
|
||||
useFetchNextDocumentList,
|
||||
useSetNextDocumentStatus,
|
||||
} from '@/hooks/document-hooks';
|
||||
import { useSetSelectedRecord } from '@/hooks/logic-hooks';
|
||||
import { useSelectParserList } from '@/hooks/user-setting-hooks';
|
||||
import { getExtension } from '@/utils/document-util';
|
||||
import { Divider, Flex, Switch, Table, Tooltip, Typography } from 'antd';
|
||||
import type { ColumnsType } from 'antd/es/table';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import CreateFileModal from './create-file-modal';
|
||||
import DocumentToolbar from './document-toolbar';
|
||||
import {
|
||||
useChangeDocumentParser,
|
||||
useCreateEmptyDocument,
|
||||
useGetRowSelection,
|
||||
useHandleUploadDocument,
|
||||
useHandleWebCrawl,
|
||||
useNavigateToOtherPage,
|
||||
useRenameDocument,
|
||||
useShowMetaModal,
|
||||
} from './hooks';
|
||||
import ParsingActionCell from './parsing-action-cell';
|
||||
import ParsingStatusCell from './parsing-status-cell';
|
||||
import RenameModal from './rename-modal';
|
||||
import WebCrawlModal from './web-crawl-modal';
|
||||
|
||||
import FileUploadModal from '@/components/file-upload-modal';
|
||||
import { RunningStatus } from '@/constants/knowledge';
|
||||
import { IDocumentInfo } from '@/interfaces/database/document';
|
||||
import { formatDate } from '@/utils/date';
|
||||
import { CircleHelp } from 'lucide-react';
|
||||
import styles from './index.less';
|
||||
import { SetMetaModal } from './set-meta-modal';
|
||||
|
||||
const { Text } = Typography;
|
||||
|
||||
const KnowledgeFile = () => {
|
||||
const { searchString, documents, pagination, handleInputChange } =
|
||||
useFetchNextDocumentList();
|
||||
const parserList = useSelectParserList();
|
||||
const { setDocumentStatus } = useSetNextDocumentStatus();
|
||||
const { toChunk } = useNavigateToOtherPage();
|
||||
const { currentRecord, setRecord } = useSetSelectedRecord<IDocumentInfo>();
|
||||
const {
|
||||
renameLoading,
|
||||
onRenameOk,
|
||||
renameVisible,
|
||||
hideRenameModal,
|
||||
showRenameModal,
|
||||
} = useRenameDocument(currentRecord.id);
|
||||
const {
|
||||
createLoading,
|
||||
onCreateOk,
|
||||
createVisible,
|
||||
hideCreateModal,
|
||||
showCreateModal,
|
||||
} = useCreateEmptyDocument();
|
||||
const {
|
||||
changeParserLoading,
|
||||
onChangeParserOk,
|
||||
changeParserVisible,
|
||||
hideChangeParserModal,
|
||||
showChangeParserModal,
|
||||
} = useChangeDocumentParser(currentRecord.id);
|
||||
const {
|
||||
documentUploadVisible,
|
||||
hideDocumentUploadModal,
|
||||
showDocumentUploadModal,
|
||||
onDocumentUploadOk,
|
||||
documentUploadLoading,
|
||||
uploadFileList,
|
||||
setUploadFileList,
|
||||
uploadProgress,
|
||||
setUploadProgress,
|
||||
} = useHandleUploadDocument();
|
||||
const {
|
||||
webCrawlUploadVisible,
|
||||
hideWebCrawlUploadModal,
|
||||
showWebCrawlUploadModal,
|
||||
onWebCrawlUploadOk,
|
||||
webCrawlUploadLoading,
|
||||
} = useHandleWebCrawl();
|
||||
const { t } = useTranslation('translation', {
|
||||
keyPrefix: 'knowledgeDetails',
|
||||
});
|
||||
|
||||
const {
|
||||
showSetMetaModal,
|
||||
hideSetMetaModal,
|
||||
setMetaVisible,
|
||||
setMetaLoading,
|
||||
onSetMetaModalOk,
|
||||
} = useShowMetaModal(currentRecord.id);
|
||||
|
||||
const rowSelection = useGetRowSelection();
|
||||
|
||||
const columns: ColumnsType<IDocumentInfo> = [
|
||||
{
|
||||
title: t('name'),
|
||||
dataIndex: 'name',
|
||||
key: 'name',
|
||||
fixed: 'left',
|
||||
render: (text: any, { id, thumbnail, name }) => (
|
||||
<div className={styles.toChunks} onClick={() => toChunk(id)}>
|
||||
<Flex gap={10} align="center">
|
||||
{thumbnail ? (
|
||||
<img className={styles.img} src={thumbnail} alt="" />
|
||||
) : (
|
||||
<SvgIcon
|
||||
name={`file-icon/${getExtension(name)}`}
|
||||
width={24}
|
||||
></SvgIcon>
|
||||
)}
|
||||
<Text ellipsis={{ tooltip: text }} className={styles.nameText}>
|
||||
{text}
|
||||
</Text>
|
||||
</Flex>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
title: t('chunkNumber'),
|
||||
dataIndex: 'chunk_num',
|
||||
key: 'chunk_num',
|
||||
},
|
||||
{
|
||||
title: t('uploadDate'),
|
||||
dataIndex: 'create_time',
|
||||
key: 'create_time',
|
||||
render(value) {
|
||||
return formatDate(value);
|
||||
},
|
||||
},
|
||||
{
|
||||
title: t('chunkMethod'),
|
||||
dataIndex: 'parser_id',
|
||||
key: 'parser_id',
|
||||
render: (text) => {
|
||||
return parserList.find((x) => x.value === text)?.label;
|
||||
},
|
||||
},
|
||||
{
|
||||
title: t('enabled'),
|
||||
key: 'status',
|
||||
dataIndex: 'status',
|
||||
render: (_, { status, id }) => (
|
||||
<>
|
||||
<Switch
|
||||
checked={status === '1'}
|
||||
onChange={(e) => {
|
||||
setDocumentStatus({ status: e, documentId: id });
|
||||
}}
|
||||
/>
|
||||
</>
|
||||
),
|
||||
},
|
||||
{
|
||||
title: (
|
||||
<span className="flex items-center gap-2">
|
||||
{t('parsingStatus')}
|
||||
<Tooltip title={t('parsingStatusTip')}>
|
||||
<CircleHelp className="size-3" />
|
||||
</Tooltip>
|
||||
</span>
|
||||
),
|
||||
dataIndex: 'run',
|
||||
key: 'run',
|
||||
filters: Object.values(RunningStatus).map((value) => ({
|
||||
text: t(`runningStatus${value}`),
|
||||
value: value,
|
||||
})),
|
||||
onFilter: (value, record: IDocumentInfo) => record.run === value,
|
||||
render: (text, record) => {
|
||||
return <ParsingStatusCell record={record}></ParsingStatusCell>;
|
||||
},
|
||||
},
|
||||
{
|
||||
title: t('action'),
|
||||
key: 'action',
|
||||
render: (_, record) => (
|
||||
<ParsingActionCell
|
||||
setCurrentRecord={setRecord}
|
||||
showRenameModal={showRenameModal}
|
||||
showChangeParserModal={showChangeParserModal}
|
||||
showSetMetaModal={showSetMetaModal}
|
||||
record={record}
|
||||
></ParsingActionCell>
|
||||
),
|
||||
},
|
||||
];
|
||||
|
||||
const finalColumns = columns.map((x) => ({
|
||||
...x,
|
||||
className: `${styles.column}`,
|
||||
}));
|
||||
|
||||
return (
|
||||
<div className={styles.datasetWrapper}>
|
||||
<h3>{t('dataset')}</h3>
|
||||
<p>{t('datasetDescription')}</p>
|
||||
<Divider></Divider>
|
||||
<DocumentToolbar
|
||||
selectedRowKeys={rowSelection.selectedRowKeys as string[]}
|
||||
showCreateModal={showCreateModal}
|
||||
showWebCrawlModal={showWebCrawlUploadModal}
|
||||
showDocumentUploadModal={showDocumentUploadModal}
|
||||
searchString={searchString}
|
||||
handleInputChange={handleInputChange}
|
||||
documents={documents}
|
||||
></DocumentToolbar>
|
||||
<Table
|
||||
rowKey="id"
|
||||
columns={finalColumns}
|
||||
dataSource={documents}
|
||||
pagination={pagination}
|
||||
rowSelection={rowSelection}
|
||||
className={styles.documentTable}
|
||||
scroll={{ scrollToFirstRowOnChange: true, x: 1300 }}
|
||||
/>
|
||||
<CreateFileModal
|
||||
visible={createVisible}
|
||||
hideModal={hideCreateModal}
|
||||
loading={createLoading}
|
||||
onOk={onCreateOk}
|
||||
/>
|
||||
<ChunkMethodModal
|
||||
documentId={currentRecord.id}
|
||||
parserId={currentRecord.parser_id}
|
||||
parserConfig={currentRecord.parser_config}
|
||||
documentExtension={getExtension(currentRecord.name)}
|
||||
onOk={onChangeParserOk}
|
||||
visible={changeParserVisible}
|
||||
hideModal={hideChangeParserModal}
|
||||
loading={changeParserLoading}
|
||||
/>
|
||||
<RenameModal
|
||||
visible={renameVisible}
|
||||
onOk={onRenameOk}
|
||||
loading={renameLoading}
|
||||
hideModal={hideRenameModal}
|
||||
initialName={currentRecord.name}
|
||||
></RenameModal>
|
||||
<FileUploadModal
|
||||
visible={documentUploadVisible}
|
||||
hideModal={hideDocumentUploadModal}
|
||||
loading={documentUploadLoading}
|
||||
onOk={onDocumentUploadOk}
|
||||
uploadFileList={uploadFileList}
|
||||
setUploadFileList={setUploadFileList}
|
||||
uploadProgress={uploadProgress}
|
||||
setUploadProgress={setUploadProgress}
|
||||
></FileUploadModal>
|
||||
<WebCrawlModal
|
||||
visible={webCrawlUploadVisible}
|
||||
hideModal={hideWebCrawlUploadModal}
|
||||
loading={webCrawlUploadLoading}
|
||||
onOk={onWebCrawlUploadOk}
|
||||
></WebCrawlModal>
|
||||
{setMetaVisible && (
|
||||
<SetMetaModal
|
||||
visible={setMetaVisible}
|
||||
hideModal={hideSetMetaModal}
|
||||
onOk={onSetMetaModalOk}
|
||||
loading={setMetaLoading}
|
||||
initialMetaData={currentRecord.meta_fields}
|
||||
></SetMetaModal>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default KnowledgeFile;
|
||||
|
|
@ -1,3 +0,0 @@
|
|||
.iconButton {
|
||||
padding: 4px 8px;
|
||||
}
|
||||
|
|
@ -1,149 +0,0 @@
|
|||
import { useShowDeleteConfirm, useTranslate } from '@/hooks/common-hooks';
|
||||
import { useRemoveNextDocument } from '@/hooks/document-hooks';
|
||||
import { IDocumentInfo } from '@/interfaces/database/document';
|
||||
import { downloadDocument } from '@/utils/file-util';
|
||||
import {
|
||||
DeleteOutlined,
|
||||
DownloadOutlined,
|
||||
EditOutlined,
|
||||
ToolOutlined,
|
||||
} from '@ant-design/icons';
|
||||
import { Button, Dropdown, MenuProps, Space, Tooltip } from 'antd';
|
||||
import { isParserRunning } from '../utils';
|
||||
|
||||
import { useCallback } from 'react';
|
||||
import { DocumentType } from '../constant';
|
||||
import styles from './index.less';
|
||||
|
||||
interface IProps {
|
||||
record: IDocumentInfo;
|
||||
setCurrentRecord: (record: IDocumentInfo) => void;
|
||||
showRenameModal: () => void;
|
||||
showChangeParserModal: () => void;
|
||||
showSetMetaModal: () => void;
|
||||
}
|
||||
|
||||
const ParsingActionCell = ({
|
||||
record,
|
||||
setCurrentRecord,
|
||||
showRenameModal,
|
||||
showChangeParserModal,
|
||||
showSetMetaModal,
|
||||
}: IProps) => {
|
||||
const documentId = record.id;
|
||||
const isRunning = isParserRunning(record.run);
|
||||
const { t } = useTranslate('knowledgeDetails');
|
||||
const { removeDocument } = useRemoveNextDocument();
|
||||
const showDeleteConfirm = useShowDeleteConfirm();
|
||||
const isVirtualDocument = record.type === DocumentType.Virtual;
|
||||
|
||||
const onRmDocument = () => {
|
||||
if (!isRunning) {
|
||||
showDeleteConfirm({
|
||||
onOk: () => removeDocument([documentId]),
|
||||
content: record?.parser_config?.graphrag?.use_graphrag
|
||||
? t('deleteDocumentConfirmContent')
|
||||
: '',
|
||||
});
|
||||
}
|
||||
};
|
||||
|
||||
const onDownloadDocument = () => {
|
||||
downloadDocument({
|
||||
id: documentId,
|
||||
filename: record.name,
|
||||
});
|
||||
};
|
||||
|
||||
const setRecord = useCallback(() => {
|
||||
setCurrentRecord(record);
|
||||
}, [record, setCurrentRecord]);
|
||||
|
||||
const onShowRenameModal = () => {
|
||||
setRecord();
|
||||
showRenameModal();
|
||||
};
|
||||
const onShowChangeParserModal = () => {
|
||||
setRecord();
|
||||
showChangeParserModal();
|
||||
};
|
||||
|
||||
const onShowSetMetaModal = useCallback(() => {
|
||||
setRecord();
|
||||
showSetMetaModal();
|
||||
}, [setRecord, showSetMetaModal]);
|
||||
|
||||
const chunkItems: MenuProps['items'] = [
|
||||
{
|
||||
key: '1',
|
||||
label: (
|
||||
<div className="flex flex-col">
|
||||
<Button type="link" onClick={onShowChangeParserModal}>
|
||||
{t('chunkMethod')}
|
||||
</Button>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '2',
|
||||
label: (
|
||||
<div className="flex flex-col">
|
||||
<Button type="link" onClick={onShowSetMetaModal}>
|
||||
{t('setMetaData')}
|
||||
</Button>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
];
|
||||
|
||||
return (
|
||||
<Space size={0}>
|
||||
{isVirtualDocument || (
|
||||
<Dropdown
|
||||
menu={{ items: chunkItems }}
|
||||
trigger={['click']}
|
||||
disabled={isRunning || record.parser_id === 'tag'}
|
||||
>
|
||||
<Button type="text" className={styles.iconButton}>
|
||||
<ToolOutlined size={20} />
|
||||
</Button>
|
||||
</Dropdown>
|
||||
)}
|
||||
<Tooltip title={t('rename', { keyPrefix: 'common' })}>
|
||||
<Button
|
||||
type="text"
|
||||
disabled={isRunning}
|
||||
onClick={onShowRenameModal}
|
||||
className={styles.iconButton}
|
||||
>
|
||||
<EditOutlined size={20} />
|
||||
</Button>
|
||||
</Tooltip>
|
||||
<Tooltip title={t('delete', { keyPrefix: 'common' })}>
|
||||
<Button
|
||||
type="text"
|
||||
disabled={isRunning}
|
||||
onClick={onRmDocument}
|
||||
className={styles.iconButton}
|
||||
>
|
||||
<DeleteOutlined size={20} />
|
||||
</Button>
|
||||
</Tooltip>
|
||||
{isVirtualDocument || (
|
||||
<Tooltip title={t('download', { keyPrefix: 'common' })}>
|
||||
<Button
|
||||
type="text"
|
||||
disabled={isRunning}
|
||||
onClick={onDownloadDocument}
|
||||
className={styles.iconButton}
|
||||
>
|
||||
<DownloadOutlined size={20} />
|
||||
</Button>
|
||||
</Tooltip>
|
||||
)}
|
||||
</Space>
|
||||
);
|
||||
};
|
||||
|
||||
export default ParsingActionCell;
|
||||
|
|
@ -1,36 +0,0 @@
|
|||
.popoverContent {
|
||||
width: 40vw;
|
||||
|
||||
.popoverContentItem {
|
||||
display: flex;
|
||||
gap: 10px;
|
||||
}
|
||||
|
||||
.popoverContentText {
|
||||
white-space: pre-line;
|
||||
max-height: 50vh;
|
||||
overflow: auto;
|
||||
.popoverContentErrorLabel {
|
||||
color: red;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.operationIcon {
|
||||
text-align: center;
|
||||
display: flex;
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
}
|
||||
}
|
||||
.operationIconSpin {
|
||||
animation: spin 1s linear infinite;
|
||||
@keyframes spin {
|
||||
0% {
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
100% {
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -1,143 +0,0 @@
|
|||
import { ReactComponent as CancelIcon } from '@/assets/svg/cancel.svg';
|
||||
import { ReactComponent as RefreshIcon } from '@/assets/svg/refresh.svg';
|
||||
import { ReactComponent as RunIcon } from '@/assets/svg/run.svg';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { IDocumentInfo } from '@/interfaces/database/document';
|
||||
import {
|
||||
Badge,
|
||||
DescriptionsProps,
|
||||
Flex,
|
||||
Popconfirm,
|
||||
Popover,
|
||||
Space,
|
||||
Tag,
|
||||
} from 'antd';
|
||||
import classNames from 'classnames';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import reactStringReplace from 'react-string-replace';
|
||||
import { DocumentType, RunningStatus, RunningStatusMap } from '../constant';
|
||||
import { useHandleRunDocumentByIds } from '../hooks';
|
||||
import { isParserRunning } from '../utils';
|
||||
import styles from './index.less';
|
||||
|
||||
const iconMap = {
|
||||
[RunningStatus.UNSTART]: RunIcon,
|
||||
[RunningStatus.RUNNING]: CancelIcon,
|
||||
[RunningStatus.CANCEL]: RefreshIcon,
|
||||
[RunningStatus.DONE]: RefreshIcon,
|
||||
[RunningStatus.FAIL]: RefreshIcon,
|
||||
};
|
||||
|
||||
interface IProps {
|
||||
record: IDocumentInfo;
|
||||
}
|
||||
|
||||
const PopoverContent = ({ record }: IProps) => {
|
||||
const { t } = useTranslate('knowledgeDetails');
|
||||
|
||||
const replaceText = (text: string) => {
|
||||
// Remove duplicate \n
|
||||
const nextText = text.replace(/(\n)\1+/g, '$1');
|
||||
|
||||
const replacedText = reactStringReplace(
|
||||
nextText,
|
||||
/(\[ERROR\].+\s)/g,
|
||||
(match, i) => {
|
||||
return (
|
||||
<span key={i} className={styles.popoverContentErrorLabel}>
|
||||
{match}
|
||||
</span>
|
||||
);
|
||||
},
|
||||
);
|
||||
|
||||
return replacedText;
|
||||
};
|
||||
|
||||
const items: DescriptionsProps['items'] = [
|
||||
{
|
||||
key: 'process_begin_at',
|
||||
label: t('processBeginAt'),
|
||||
children: record.process_begin_at,
|
||||
},
|
||||
{
|
||||
key: 'process_duration',
|
||||
label: t('processDuration'),
|
||||
children: `${record.process_duration.toFixed(2)} s`,
|
||||
},
|
||||
{
|
||||
key: 'progress_msg',
|
||||
label: t('progressMsg'),
|
||||
children: replaceText(record.progress_msg.trim()),
|
||||
},
|
||||
];
|
||||
|
||||
return (
|
||||
<Flex vertical className={styles.popoverContent}>
|
||||
{items.map((x, idx) => {
|
||||
return (
|
||||
<div key={x.key} className={idx < 2 ? styles.popoverContentItem : ''}>
|
||||
<b>{x.label}:</b>
|
||||
<div className={styles.popoverContentText}>{x.children}</div>
|
||||
</div>
|
||||
);
|
||||
})}
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
export const ParsingStatusCell = ({ record }: IProps) => {
|
||||
const text = record.run;
|
||||
const runningStatus = RunningStatusMap[text];
|
||||
const { t } = useTranslation();
|
||||
const { handleRunDocumentByIds } = useHandleRunDocumentByIds(record.id);
|
||||
|
||||
const isRunning = isParserRunning(text);
|
||||
|
||||
const OperationIcon = iconMap[text];
|
||||
|
||||
const label = t(`knowledgeDetails.runningStatus${text}`);
|
||||
|
||||
const handleOperationIconClick =
|
||||
(shouldDelete: boolean = false) =>
|
||||
() => {
|
||||
handleRunDocumentByIds(record.id, isRunning, shouldDelete);
|
||||
};
|
||||
|
||||
return record.type === DocumentType.Virtual ? null : (
|
||||
<Flex justify={'space-between'} align="center">
|
||||
<Popover content={<PopoverContent record={record}></PopoverContent>}>
|
||||
<Tag color={runningStatus.color}>
|
||||
{isRunning ? (
|
||||
<Space>
|
||||
<Badge color={runningStatus.color} />
|
||||
{label}
|
||||
<span>{(record.progress * 100).toFixed(2)}%</span>
|
||||
</Space>
|
||||
) : (
|
||||
label
|
||||
)}
|
||||
</Tag>
|
||||
</Popover>
|
||||
<Popconfirm
|
||||
title={t(`knowledgeDetails.redo`, { chunkNum: record.chunk_num })}
|
||||
onConfirm={handleOperationIconClick(true)}
|
||||
onCancel={handleOperationIconClick(false)}
|
||||
disabled={record.chunk_num === 0}
|
||||
okText={t('common.yes')}
|
||||
cancelText={t('common.no')}
|
||||
>
|
||||
<div
|
||||
className={classNames(styles.operationIcon)}
|
||||
onClick={
|
||||
record.chunk_num === 0 ? handleOperationIconClick(false) : () => {}
|
||||
}
|
||||
>
|
||||
<OperationIcon />
|
||||
</div>
|
||||
</Popconfirm>
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
export default ParsingStatusCell;
|
||||
|
|
@ -1,75 +0,0 @@
|
|||
import { IModalManagerChildrenProps } from '@/components/modal-manager';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { Form, Input, Modal } from 'antd';
|
||||
import { useEffect } from 'react';
|
||||
|
||||
interface IProps extends Omit<IModalManagerChildrenProps, 'showModal'> {
|
||||
loading: boolean;
|
||||
initialName: string;
|
||||
onOk: (name: string) => void;
|
||||
showModal?(): void;
|
||||
}
|
||||
|
||||
const RenameModal = ({
|
||||
visible,
|
||||
onOk,
|
||||
loading,
|
||||
initialName,
|
||||
hideModal,
|
||||
}: IProps) => {
|
||||
const [form] = Form.useForm();
|
||||
const { t } = useTranslate('common');
|
||||
type FieldType = {
|
||||
name?: string;
|
||||
};
|
||||
|
||||
const handleOk = async () => {
|
||||
const ret = await form.validateFields();
|
||||
onOk(ret.name);
|
||||
};
|
||||
|
||||
const onFinish = (values: any) => {
|
||||
console.log('Success:', values);
|
||||
};
|
||||
|
||||
const onFinishFailed = (errorInfo: any) => {
|
||||
console.log('Failed:', errorInfo);
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
if (visible) {
|
||||
form.setFieldValue('name', initialName);
|
||||
}
|
||||
}, [initialName, form, visible]);
|
||||
|
||||
return (
|
||||
<Modal
|
||||
title={t('rename')}
|
||||
open={visible}
|
||||
onOk={handleOk}
|
||||
onCancel={hideModal}
|
||||
okButtonProps={{ loading }}
|
||||
>
|
||||
<Form
|
||||
name="basic"
|
||||
labelCol={{ span: 4 }}
|
||||
wrapperCol={{ span: 20 }}
|
||||
style={{ maxWidth: 600 }}
|
||||
onFinish={onFinish}
|
||||
onFinishFailed={onFinishFailed}
|
||||
autoComplete="off"
|
||||
form={form}
|
||||
>
|
||||
<Form.Item<FieldType>
|
||||
label={t('name')}
|
||||
name="name"
|
||||
rules={[{ required: true, message: t('namePlaceholder') }]}
|
||||
>
|
||||
<Input />
|
||||
</Form.Item>
|
||||
</Form>
|
||||
</Modal>
|
||||
);
|
||||
};
|
||||
|
||||
export default RenameModal;
|
||||
|
|
@ -1,81 +0,0 @@
|
|||
import { IModalProps } from '@/interfaces/common';
|
||||
import { IDocumentInfo } from '@/interfaces/database/document';
|
||||
import Editor, { loader } from '@monaco-editor/react';
|
||||
|
||||
import { Form, Modal } from 'antd';
|
||||
import DOMPurify from 'dompurify';
|
||||
import { useCallback, useEffect } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
|
||||
loader.config({ paths: { vs: '/vs' } });
|
||||
|
||||
type FieldType = {
|
||||
meta?: string;
|
||||
};
|
||||
|
||||
export function SetMetaModal({
|
||||
visible,
|
||||
hideModal,
|
||||
onOk,
|
||||
initialMetaData,
|
||||
}: IModalProps<any> & { initialMetaData?: IDocumentInfo['meta_fields'] }) {
|
||||
const { t } = useTranslation();
|
||||
const [form] = Form.useForm();
|
||||
|
||||
const handleOk = useCallback(async () => {
|
||||
const values = await form.validateFields();
|
||||
onOk?.(values.meta);
|
||||
}, [form, onOk]);
|
||||
|
||||
useEffect(() => {
|
||||
form.setFieldValue('meta', JSON.stringify(initialMetaData, null, 4));
|
||||
}, [form, initialMetaData]);
|
||||
|
||||
return (
|
||||
<Modal
|
||||
title={t('knowledgeDetails.setMetaData')}
|
||||
open={visible}
|
||||
onOk={handleOk}
|
||||
onCancel={hideModal}
|
||||
>
|
||||
<Form
|
||||
name="basic"
|
||||
initialValues={{ remember: true }}
|
||||
autoComplete="off"
|
||||
layout={'vertical'}
|
||||
form={form}
|
||||
>
|
||||
<Form.Item<FieldType>
|
||||
label={t('knowledgeDetails.metaData')}
|
||||
name="meta"
|
||||
rules={[
|
||||
{
|
||||
required: true,
|
||||
validator(rule, value) {
|
||||
try {
|
||||
JSON.parse(value);
|
||||
return Promise.resolve();
|
||||
} catch (error) {
|
||||
return Promise.reject(
|
||||
new Error(t('knowledgeDetails.pleaseInputJson')),
|
||||
);
|
||||
}
|
||||
},
|
||||
},
|
||||
]}
|
||||
tooltip={
|
||||
<div
|
||||
dangerouslySetInnerHTML={{
|
||||
__html: DOMPurify.sanitize(
|
||||
t('knowledgeDetails.documentMetaTips'),
|
||||
),
|
||||
}}
|
||||
></div>
|
||||
}
|
||||
>
|
||||
<Editor height={200} defaultLanguage="json" theme="vs-dark" />
|
||||
</Form.Item>
|
||||
</Form>
|
||||
</Modal>
|
||||
);
|
||||
}
|
||||
|
|
@ -1,6 +0,0 @@
|
|||
import { RunningStatus } from './constant';
|
||||
|
||||
export const isParserRunning = (text: RunningStatus) => {
|
||||
const isRunning = text === RunningStatus.RUNNING;
|
||||
return isRunning;
|
||||
};
|
||||
|
|
@ -1,67 +0,0 @@
|
|||
import { IModalManagerChildrenProps } from '@/components/modal-manager';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { Form, Input, Modal } from 'antd';
|
||||
import React from 'react';
|
||||
|
||||
interface IProps extends Omit<IModalManagerChildrenProps, 'showModal'> {
|
||||
loading: boolean;
|
||||
onOk: (name: string, url: string) => void;
|
||||
showModal?(): void;
|
||||
}
|
||||
|
||||
const WebCrawlModal: React.FC<IProps> = ({ visible, hideModal, onOk }) => {
|
||||
const [form] = Form.useForm();
|
||||
const { t } = useTranslate('knowledgeDetails');
|
||||
const handleOk = async () => {
|
||||
const values = await form.validateFields();
|
||||
onOk(values.name, values.url);
|
||||
};
|
||||
|
||||
return (
|
||||
<Modal
|
||||
title={t('webCrawl')}
|
||||
open={visible}
|
||||
onOk={handleOk}
|
||||
onCancel={hideModal}
|
||||
>
|
||||
<Form
|
||||
form={form}
|
||||
name="validateOnly"
|
||||
labelCol={{ span: 4 }}
|
||||
wrapperCol={{ span: 20 }}
|
||||
style={{ maxWidth: 600 }}
|
||||
autoComplete="off"
|
||||
>
|
||||
<Form.Item
|
||||
label="Name"
|
||||
name="name"
|
||||
rules={[
|
||||
{ required: true, message: 'Please input name!' },
|
||||
{
|
||||
max: 10,
|
||||
message: 'The maximum length of name is 128 characters',
|
||||
},
|
||||
]}
|
||||
>
|
||||
<Input placeholder="Document name" />
|
||||
</Form.Item>
|
||||
<Form.Item
|
||||
label="URL"
|
||||
name="url"
|
||||
rules={[
|
||||
{ required: true, message: 'Please input url!' },
|
||||
{
|
||||
pattern: new RegExp(
|
||||
'(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]',
|
||||
),
|
||||
message: 'Please enter a valid URL!',
|
||||
},
|
||||
]}
|
||||
>
|
||||
<Input placeholder="https://www.baidu.com" />
|
||||
</Form.Item>
|
||||
</Form>
|
||||
</Modal>
|
||||
);
|
||||
};
|
||||
export default WebCrawlModal;
|
||||
|
|
@ -1,241 +0,0 @@
|
|||
const nodes = [
|
||||
{
|
||||
type: '"ORGANIZATION"',
|
||||
description:
|
||||
'"厦门象屿是一家公司,其营业收入和市场占有率在2018年至2022年间有所变化。"',
|
||||
source_id: '0',
|
||||
id: '"厦门象屿"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"2018年是一个时间点,标志着厦门象屿营业收入和市场占有率的记录开始。"',
|
||||
source_id: '0',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"2018"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"2019年是一个时间点,厦门象屿的营业收入和市场占有率在此期间有所变化。"',
|
||||
source_id: '0',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"2019"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"2020年是一个时间点,厦门象屿的营业收入和市场占有率在此期间有所变化。"',
|
||||
source_id: '0',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"2020"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"2021年是一个时间点,厦门象屿的营业收入和市场占有率在此期间有所变化。"',
|
||||
source_id: '0',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"2021"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"2022年是一个时间点,厦门象屿的营业收入和市场占有率在此期间有所变化。"',
|
||||
source_id: '0',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"2022"',
|
||||
},
|
||||
{
|
||||
type: '"ORGANIZATION"',
|
||||
description:
|
||||
'"厦门象屿股份有限公司是一家公司,中文简称为厦门象屿,外文名称为Xiamen Xiangyu Co.,Ltd.,外文名称缩写为Xiangyu,法定代表人为邓启东。"',
|
||||
source_id: '1',
|
||||
id: '"厦门象屿股份有限公司"',
|
||||
},
|
||||
{
|
||||
type: '"PERSON"',
|
||||
description: '"邓启东是厦门象屿股份有限公司的法定代表人。"',
|
||||
source_id: '1',
|
||||
entity_type: '"PERSON"',
|
||||
id: '"邓启东"',
|
||||
},
|
||||
{
|
||||
type: '"GEO"',
|
||||
description: '"厦门是一个地理位置,与厦门象屿股份有限公司相关。"',
|
||||
source_id: '1',
|
||||
entity_type: '"GEO"',
|
||||
id: '"厦门"',
|
||||
},
|
||||
{
|
||||
type: '"PERSON"',
|
||||
description:
|
||||
'"廖杰 is the Board Secretary, responsible for handling board-related matters and communications."',
|
||||
source_id: '2',
|
||||
id: '"廖杰"',
|
||||
},
|
||||
{
|
||||
type: '"PERSON"',
|
||||
description:
|
||||
'"史经洋 is the Securities Affairs Representative, responsible for handling securities-related matters and communications."',
|
||||
source_id: '2',
|
||||
entity_type: '"PERSON"',
|
||||
id: '"史经洋"',
|
||||
},
|
||||
{
|
||||
type: '"GEO"',
|
||||
description:
|
||||
'"A geographic location in Xiamen, specifically in the Free Trade Zone, where the company\'s office is situated."',
|
||||
source_id: '2',
|
||||
entity_type: '"GEO"',
|
||||
id: '"厦门市湖里区自由贸易试验区厦门片区"',
|
||||
},
|
||||
{
|
||||
type: '"GEO"',
|
||||
description:
|
||||
'"The building where the company\'s office is located, situated at Xiangyu Road, Xiamen."',
|
||||
source_id: '2',
|
||||
entity_type: '"GEO"',
|
||||
id: '"象屿集团大厦"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"Refers to the year 2021, used for comparing financial metrics with the year 2022."',
|
||||
source_id: '3',
|
||||
id: '"2021年"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"Refers to the year 2022, used for presenting current financial metrics and comparing them with the year 2021."',
|
||||
source_id: '3',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"2022年"',
|
||||
},
|
||||
{
|
||||
type: '"EVENT"',
|
||||
description:
|
||||
'"Indicates the focus on key financial metrics in the table, such as weighted averages and percentages."',
|
||||
source_id: '3',
|
||||
entity_type: '"EVENT"',
|
||||
id: '"主要财务指标"',
|
||||
},
|
||||
].map(({ type, ...x }) => ({ ...x }));
|
||||
|
||||
const edges = [
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿在2018年的营业收入和市场占有率被记录。"',
|
||||
source_id: '0',
|
||||
source: '"厦门象屿"',
|
||||
target: '"2018"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿在2019年的营业收入和市场占有率有所变化。"',
|
||||
source_id: '0',
|
||||
source: '"厦门象屿"',
|
||||
target: '"2019"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿在2020年的营业收入和市场占有率有所变化。"',
|
||||
source_id: '0',
|
||||
source: '"厦门象屿"',
|
||||
target: '"2020"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿在2021年的营业收入和市场占有率有所变化。"',
|
||||
source_id: '0',
|
||||
source: '"厦门象屿"',
|
||||
target: '"2021"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿在2022年的营业收入和市场占有率有所变化。"',
|
||||
source_id: '0',
|
||||
source: '"厦门象屿"',
|
||||
target: '"2022"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿股份有限公司的法定代表人是邓启东。"',
|
||||
source_id: '1',
|
||||
source: '"厦门象屿股份有限公司"',
|
||||
target: '"邓启东"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description: '"厦门象屿股份有限公司位于厦门。"',
|
||||
source_id: '1',
|
||||
source: '"厦门象屿股份有限公司"',
|
||||
target: '"厦门"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"廖杰\'s office is located in the Xiangyu Group Building, indicating his workplace."',
|
||||
source_id: '2',
|
||||
source: '"廖杰"',
|
||||
target: '"象屿集团大厦"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"廖杰 works in the Xiamen Free Trade Zone, a specific area within Xiamen."',
|
||||
source_id: '2',
|
||||
source: '"廖杰"',
|
||||
target: '"厦门市湖里区自由贸易试验区厦门片区"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"史经洋\'s office is also located in the Xiangyu Group Building, indicating his workplace."',
|
||||
source_id: '2',
|
||||
source: '"史经洋"',
|
||||
target: '"象屿集团大厦"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"史经洋 works in the Xiamen Free Trade Zone, a specific area within Xiamen."',
|
||||
source_id: '2',
|
||||
source: '"史经洋"',
|
||||
target: '"厦门市湖里区自由贸易试验区厦门片区"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"The years 2021 and 2022 are related as they are used for comparing financial metrics, showing changes and adjustments over time."',
|
||||
source_id: '3',
|
||||
source: '"2021年"',
|
||||
target: '"2022年"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"The \'主要财务指标\' is related to the year 2021 as it provides the basis for financial comparisons and adjustments."',
|
||||
source_id: '3',
|
||||
source: '"2021年"',
|
||||
target: '"主要财务指标"',
|
||||
},
|
||||
{
|
||||
weight: 2.0,
|
||||
description:
|
||||
'"The \'主要财务指标\' is related to the year 2022 as it presents the current financial metrics and their changes compared to 2021."',
|
||||
source_id: '3',
|
||||
source: '"2022年"',
|
||||
target: '"主要财务指标"',
|
||||
},
|
||||
];
|
||||
|
||||
export const graphData = {
|
||||
directed: false,
|
||||
multigraph: false,
|
||||
graph: {},
|
||||
nodes,
|
||||
edges,
|
||||
combos: [],
|
||||
};
|
||||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Reference in a new issue