| .. | ||
| cognee_01042025 | ||
| cognee_optimized_01042025 | ||
| falkor_01042025 | ||
| graphiti_01042025 | ||
| mem0_01042025 | ||
| cognee_comparison.png | ||
| hotpot_50_corpus.json | ||
| hotpot_50_qa_pairs.json | ||
| metrics_comparison.png | ||
| plot_metrics.py | ||
| README.md | ||
| requirements.txt | ||
{kind=link}
{kind=link}
Accuracy Analysis for AI Memory Systems
This repository contains a comparative analysis of three different question-answering systems: Mem0, Graphiti, and Falkor's GraphRAG-SDK. The analysis is performed using a subset of the HotpotQA dataset.
Dataset
The analysis uses two key data files:
hotpot_50_corpus.json: Contains 50 randomly selected instances from HotpotQAhotpot_50_qa_pairs.json: Contains corresponding question-answer pairs
Generating the Dataset
You can generate these files using the Cognee framework:
import json
from cognee.eval_framework.benchmark_adapters.hotpot_qa_adapter import HotpotQAAdapter
adapter = HotpotQAAdapter()
corpus_list, question_answer_pairs = adapter.load_corpus(limit=50)
with open('hotpot_50_corpus.json', 'w') as outfile:
json.dump(corpus_list, outfile)
with open('hotpot_50_qa_pairs.json', 'w') as outfile:
json.dump(question_answer_pairs, outfile)
Systems Analyzed
1. Mem0
A memory-based QA system that uses OpenAI API for answering questions with context management.
Setup and Running
- Clone the repository:
git clone https://github.com/mem0ai/mem0 - Create
.envfile with yourOPENAI_API_KEY - Copy the dataset JSON files to the repo root
- Run the analysis script:
python hotpot_qa_mem0.py
Results are available in:
metrics_output_mem0.jsonmetrics_output_mem0_direct_llm.jsonaggregate_metrics_mem0.jsonaggregate_metrics_mem0_direct_llm.json
2. Graphiti
A knowledge graph-based QA system using LangChain and Neo4j.
Setup and Running
- Clone the repository:
git clone https://github.com/getzep/graphiti.git - Ensure Neo4j is running
- Create
.envfile with:OPENAI_API_KEYNEO4J_URINEO4J_USERNEO4J_PASSWORD
- Copy the dataset JSON files to the repo root
- Run the analysis script:
python hotpot_qa_graphiti.py
Results are available in:
metrics_output_graphiti.jsonmetrics_output_graphiti_direct_llm.jsonaggregate_metrics_graphiti.jsonaggregate_metrics_graphiti_direct_llm.json
Human Evaluation
In order to ensure the highest possible accuracy of our results, we conducted a thorough human evaluation of the dataset. We had human evaluators compare responses against golden answers, and we manually reviewed each failed question to validate the results.
Since we focused on validating false negatives rather than checking for false positives, the scores might be slightly higher than a comprehensive evaluation. However, we believe this difference is relatively small and doesn't significantly impact the comparative analysis.
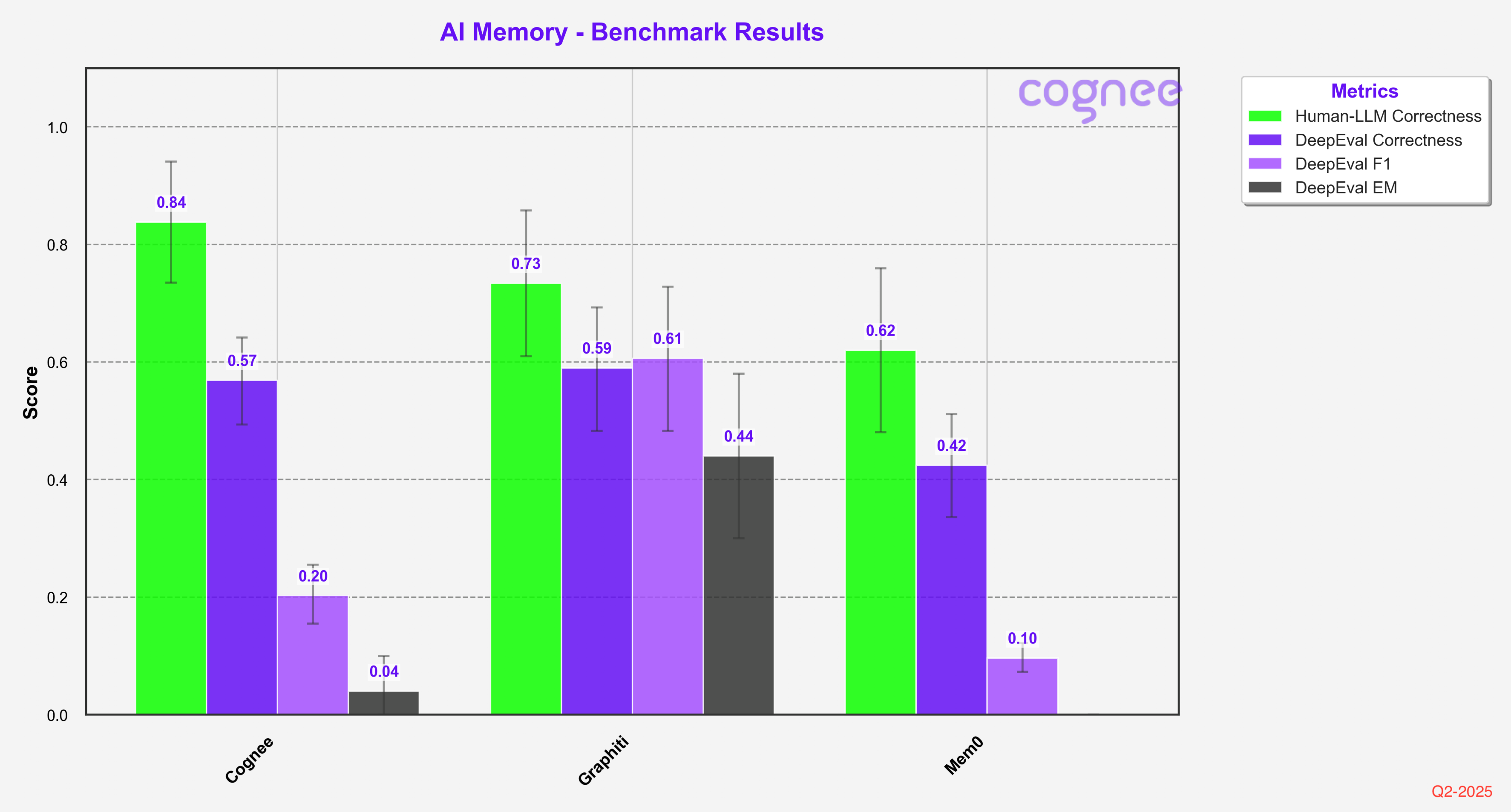
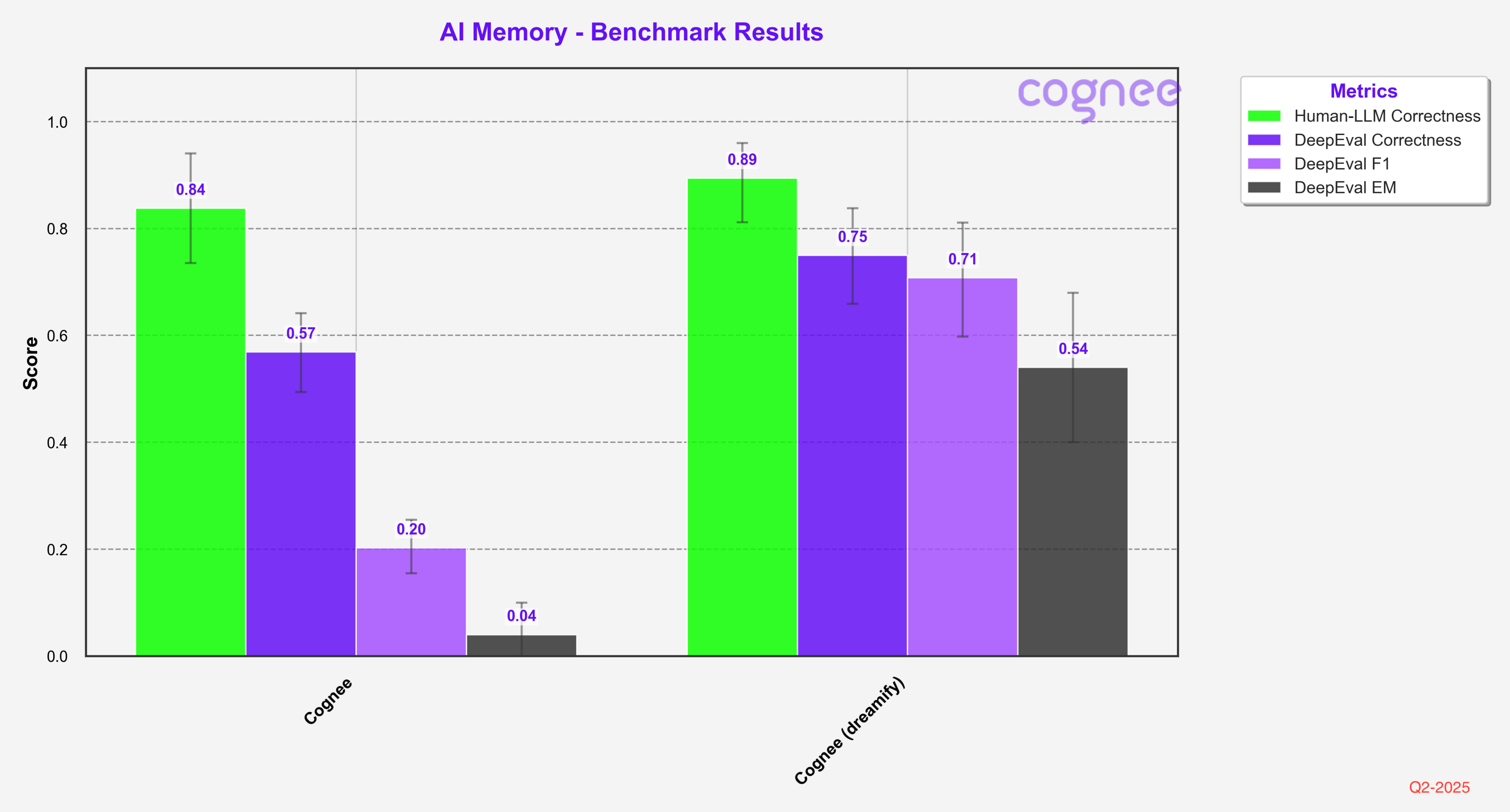
Adding Dreamify
When we enhanced Cognee with Dreamify optimization, we saw significant improvements across all evaluation metrics, particularly in DeepEval F1 and EM scores.
Problems with the Approach
- LLM as a judge metrics are not reliable measure and can indicate the overall accuracy
- F1 scores measure character matching and are too granular for use in semantic memory evaluation
- Human as a judge is labor intensive and does not scale
- Hotpot is not the hardest metric out there
Results
The results for each system are stored in separate JSON files, containing both detailed metrics and aggregate performance measures. These can be found in the respective metrics output files for each system.